はじめに
Datadog は、メトリクス・ログ・APM・ネットワーク監視などを一元的に可視化できる非常に強力な監視サービスです。一方で、何も考えずに導入・運用していると、
- 想定以上に請求額が高い
- ネットワーク回線の使用率が高い
といった状況に陥りがちです。
その大きな原因の一つがDatadog に送信されるデータ転送量です。Datadog は「どれだけデータを送ったか」に強く依存した課金体系となっており、無駄なデータ送信はそのままコスト増加につながります。
本記事では、Datadog の可観測性を維持しつつ、データ転送量を抑えてコストを削減するための実践的な方法を説明します。
Datadogをまだ触ったことがない方は、下記の記事を参考にして導入してみてください。
Datadog入門:監視とオブザーバビリティの違いから導入・設定方法まで徹底解説
データ転送量の確認方法
まずは、データ転送量を抑える前に、データ転送量を確認する方法を抑えておいてください。
Datadog Agent は、サーバやコンテナ上で動作し、以下のようなデータを Datadog の SaaS 側へ送信します。
- メトリクス(CPU、メモリ、ディスク、アプリ独自メトリクスなど)
- APM トレース(リクエスト単位の処理時間や依存関係)
- ログ(アプリケーションログ、ミドルウェアログ)
- プロセス情報、ネットワーク情報(有効化している場合)
重要なのは、「保存された量」ではなく「送信された量」そのものがコストに影響する点です。つまり、不要なデータを送信し続けている限り、ダッシュボードを見ていなくてもコストは発生しますので要注意です。
データ転送量に関するデータは、Organaization Settings の Plan & Usage より確認ができるので、定期的に確認しましょう。
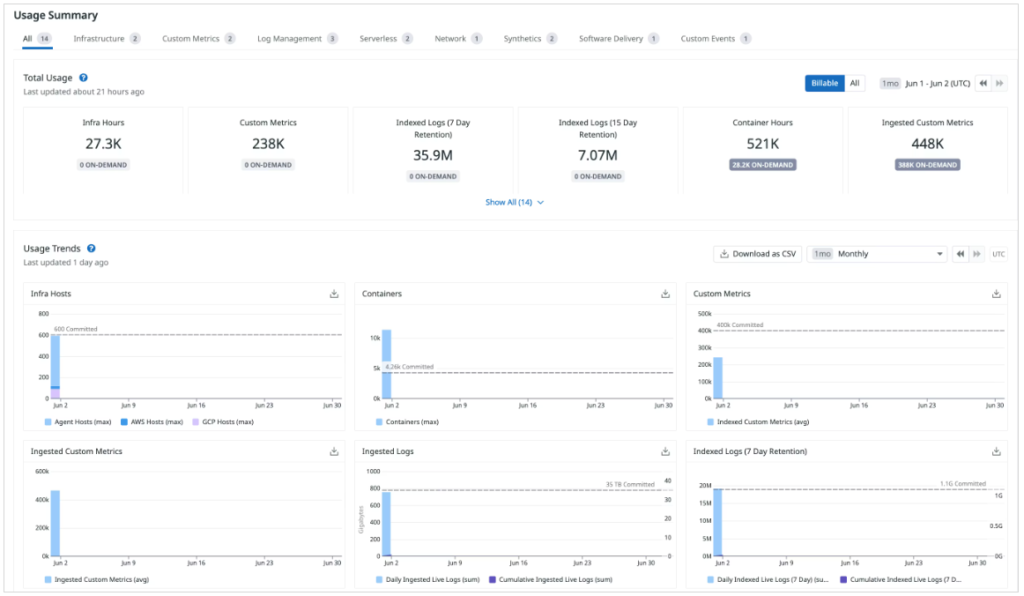
参考サイト:https://docs.datadoghq.com/account_management/plan_and_usage/usage_details/
データ転送量を抑える方法
それでは早速、機能ごとにデータ転送量を削減する方法を説明していきます。
Datadog Infrastructureのデータ転送量を削減する
Datadog Agent のチェック間隔を短くすることで、Infrastructure関連のデータ転送量を削減することが可能です。デフォルトでは15秒間隔となっていますので、この間隔を広げることが可能です。
試しに15秒間隔から60秒間隔に変更してみましょう。以下のように、datadog.yaml に min_collection_interval の設定を追加して Agentを再起動します。
[root@quiz ~]# vi /etc/datadog-agent/datadog.yaml
[root@quiz ~]# grep "min_collection_interval: 60" /etc/datadog-agent/datadog.yaml
min_collection_interval: 60
[root@quiz ~]#
[root@quiz ~]# systemctl restart datadog-agent
[root@quiz ~]#直接的にInfrastructure関連データの転送量を確認する方法は見つけられなかったのですが、間接的にデータ転送量が減っていることを確認してみましょう。
以下のように、datadog-agent status コマンドを実行することでサンプル数の累積件数確認することができます。min_collection_interval 前後で累積件数の増分を確認し、サンプル数の増加が減っていることが確認可能です。ただし、このサンプル数にはInfrastructure関連以外のデータも含まれていますので、単純にサンプル数が設定と比例するわけではないことはご留意ください。
[root@quiz ~]# datadog-agent status
~~Truncated~~
==========
Aggregator
==========
Checks Metric Sample: 5,615
Dogstatsd Metric Sample: 489
Event: 1
Events Flushed: 1
Number Of Flushes: 17
Series Flushed: 4,894
Service Check: 53
Service Checks Flushed: 69
APMのデータ転送量を抑える
APMは比較的データ転送量が多いので、適切に設定することが重要です。以下の2つの方法でデータ転送量を抑えることができますので、それぞれ説明させていただきます。
- サンプリング数の設定
- 不要なエンドポイントを除外
サンプリング数の設定
APM を有効にすると、アプリケーションへのリクエストに対して「トレース(Trace)」と呼ばれる処理の流れの情報が Datadog に送信されます。
すべてのリクエストが無制限に取り込まれるわけではなく、Datadog Agent では 1 秒間に取り込むトレース数が制御されています。デフォルトでは 1エージェントあたり 10 トレース/秒(max_traces_per_second = 10) が設定されています。
平均的なレスポンスタイムや傾向を把握することが目的であれば、大量のトレース情報を取り込む必要がないケースもあります。通常トラフィックのトレースは抑えつつ、エラー発生時のトレースは優先的に取得するといった設定が実務ではよく採用されています。用途やトラフィック量に応じて、適切なサンプリング数を設定しましょう。
それでは、サンプリング数を変更する方法をご説明します。
APM > Ingestion Control をクリックしてください。
Configure Datadog Agent Ingestion をクリックしてください。
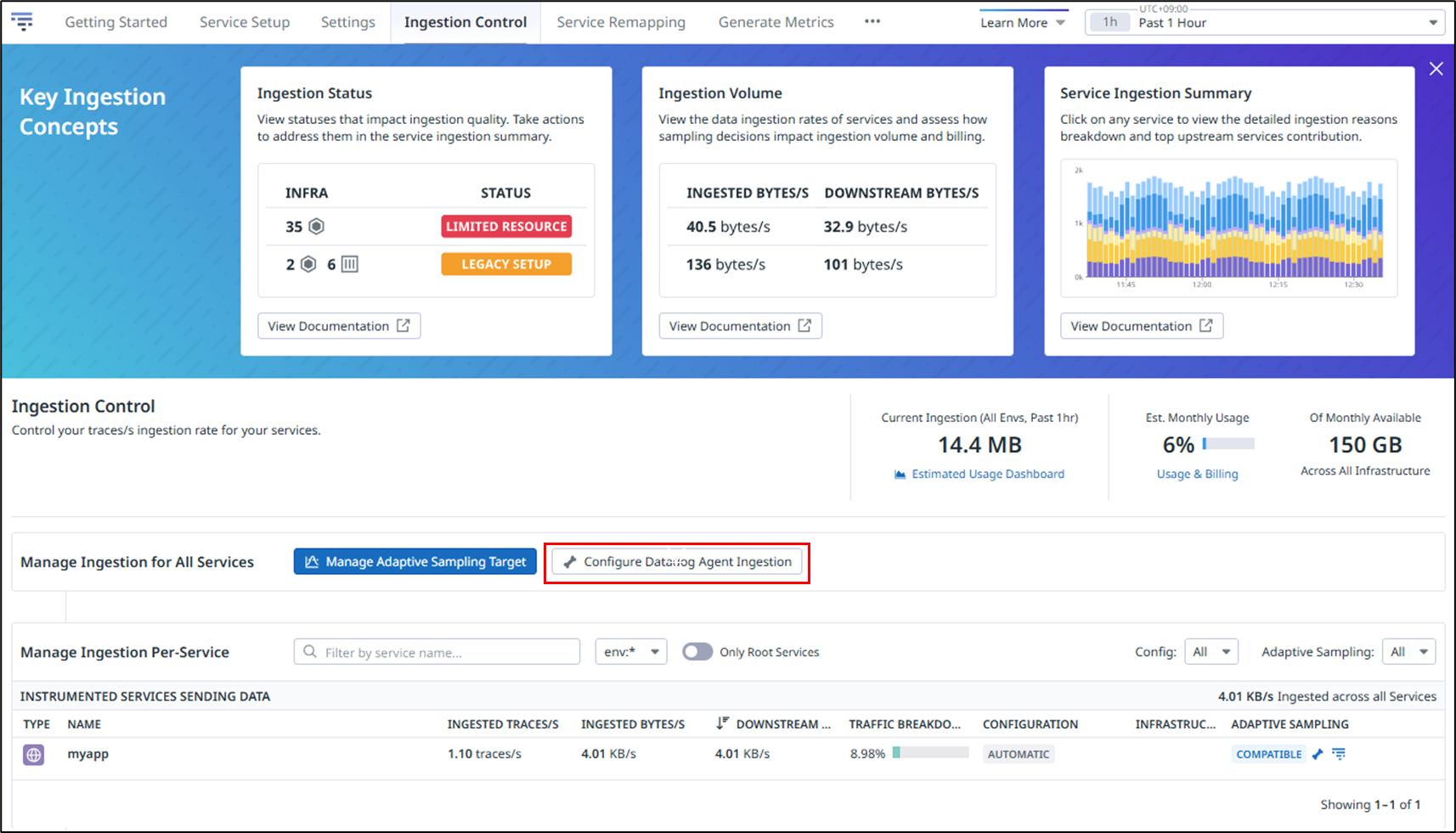
1秒間に収集するトレースの数を設定します。ここでは、Head-based SamplingとError Spans Sampling の値をデフォルト値の10から5に変更しています。
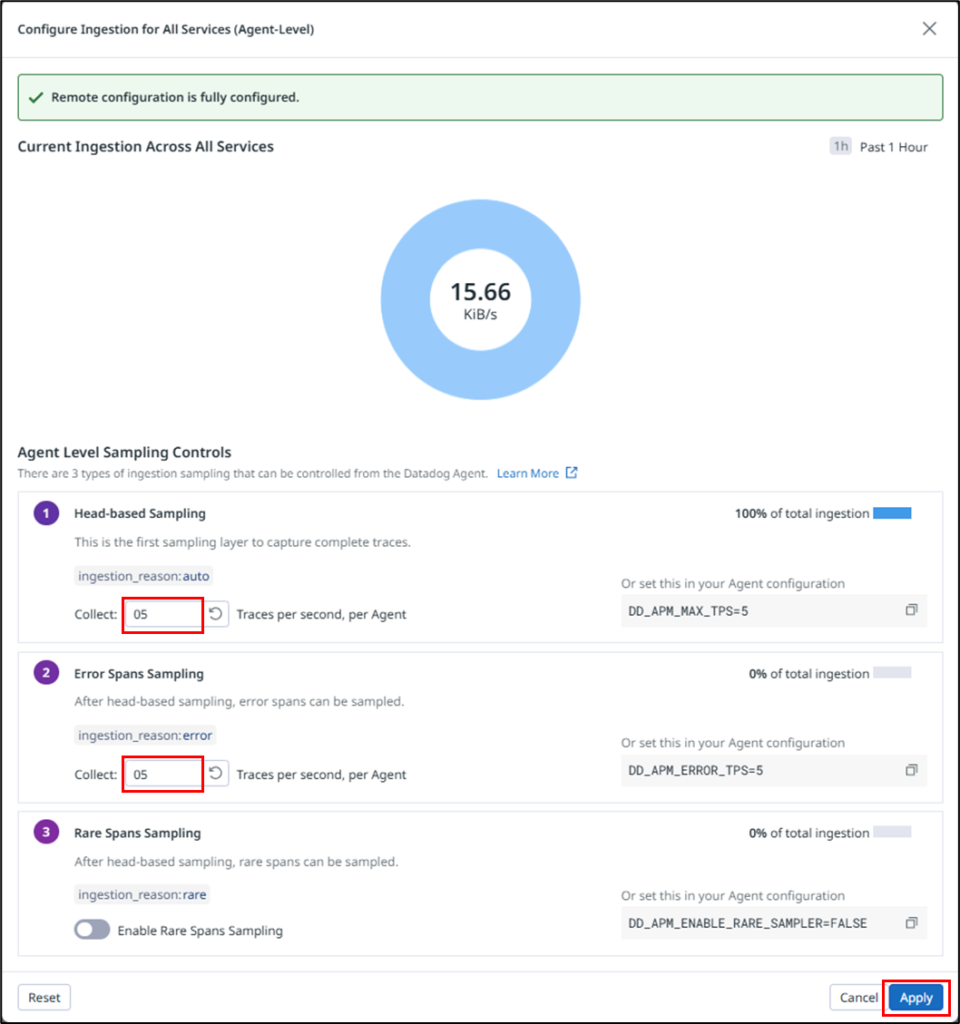
それぞれの設定項目についてご説明します。
| No. | 設定項目 | 説明 | デフォルト値 |
|---|---|---|---|
| 1 | Head-based Sampling | 受信したリクエスト全体に対して、トレースの入口(Head)でサンプリング要否を決定する設定。 | 10 Traces / s (Agentあたり) |
| 2 | Error Spans Sampling | Head-based Samplingで保持されなかったトレースのうち、error=1が付与されたスパンを含むものを優先的に追加保持する仕組み。本値を大きくすると障害調査に有効。 | 10 Traces / s (Agentあたり) |
| 3 | Rare Spans Sampling | Head-based Samplingで保持されなかったトレースのうち、出現頻度の低い resource やタグを持つレアなスパンを含むものを優先的に追加保持する仕組み。低頻度障害の調査に有効。 | Disabled |
詳細を知りたい方は、以下のDatadogのサイトを参照ください。
https://docs.datadoghq.com/ja/tracing/trace_pipeline/ingestion_mechanisms/?tab=java
それでは実際に、取り込まれたデータ量が抑えられているかを確認しましょう。
APM > Ingestion Control をクリックしたあとに、確認したいアプリケーションをクリックします。
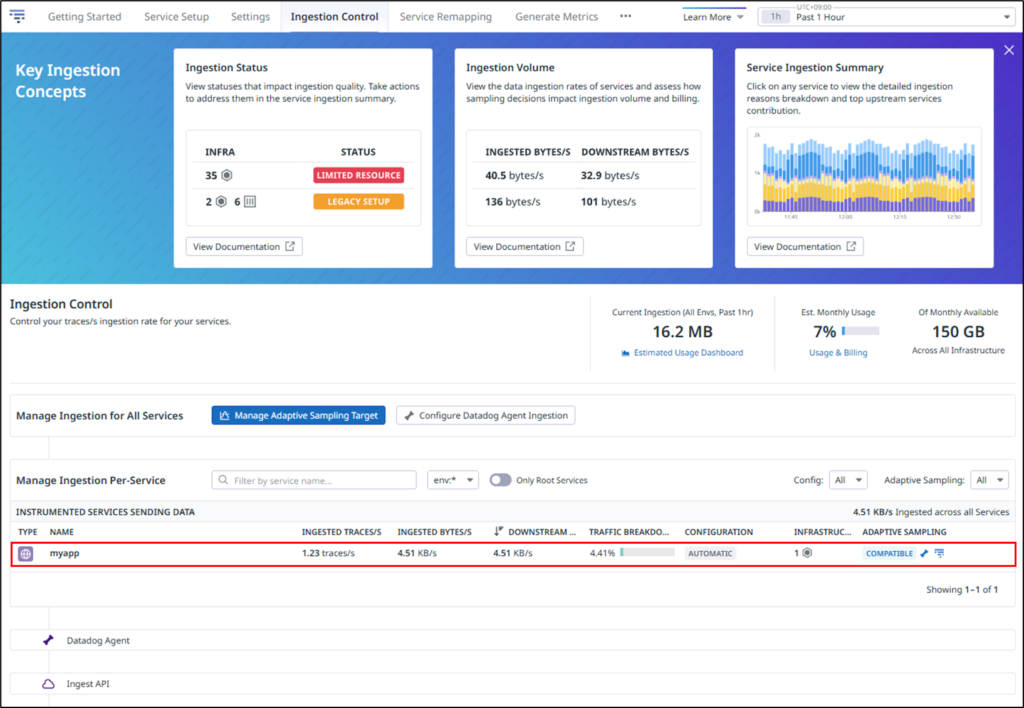
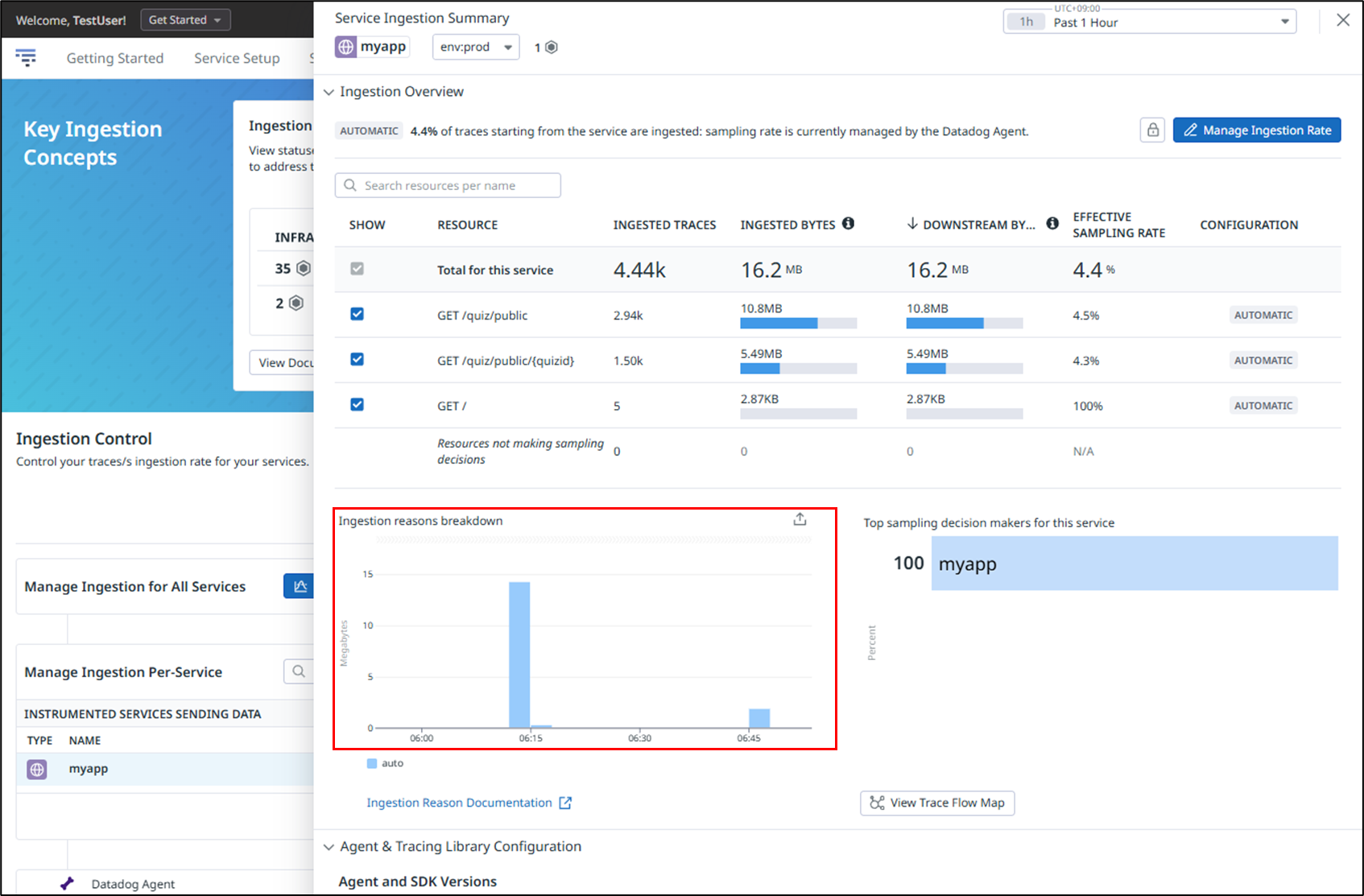
以下の通り、Ingestion reasons breakdownに取り込まれたデータ量が記録されていることが確認できます。左側のスパイクがHead-based SamplingとError Spans Sampling の値をデフォルト値の10、右側のスパイクがHead-based SamplingとError Spans Sampling の値を5にした結果となっており、サンプリング数を低くすることで取り込まれるデータ量を抑えられることが確認できました。
不要なエンドポイントを除外
ヘルスチェック用のエンドポイントや、頻繁に呼ばれる内部 API をトレース対象に含めていると、取り込まれるトレース数およびスパン数が大幅に増加します。これらは可観測性の観点で重要度が低いことが多いため、トレース対象から除外することでコスト削減効果が高くなります。
試しに、特定のURLへのアクセスをトレース対象外とする設定を入れてみましょう。
まず、現状の設定でDatadogに転送しているデータ量を確認します。
Traces > Ingesteion Control をクリックします。
対象のサービスをクリックします。
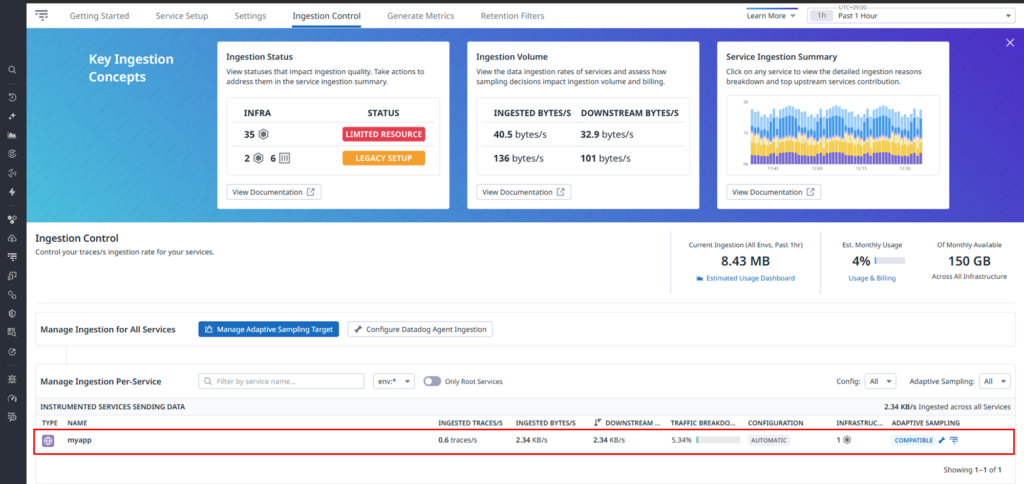
下記の通り、アクセスするリソースごとに転送しているデータ量を確認することができます。
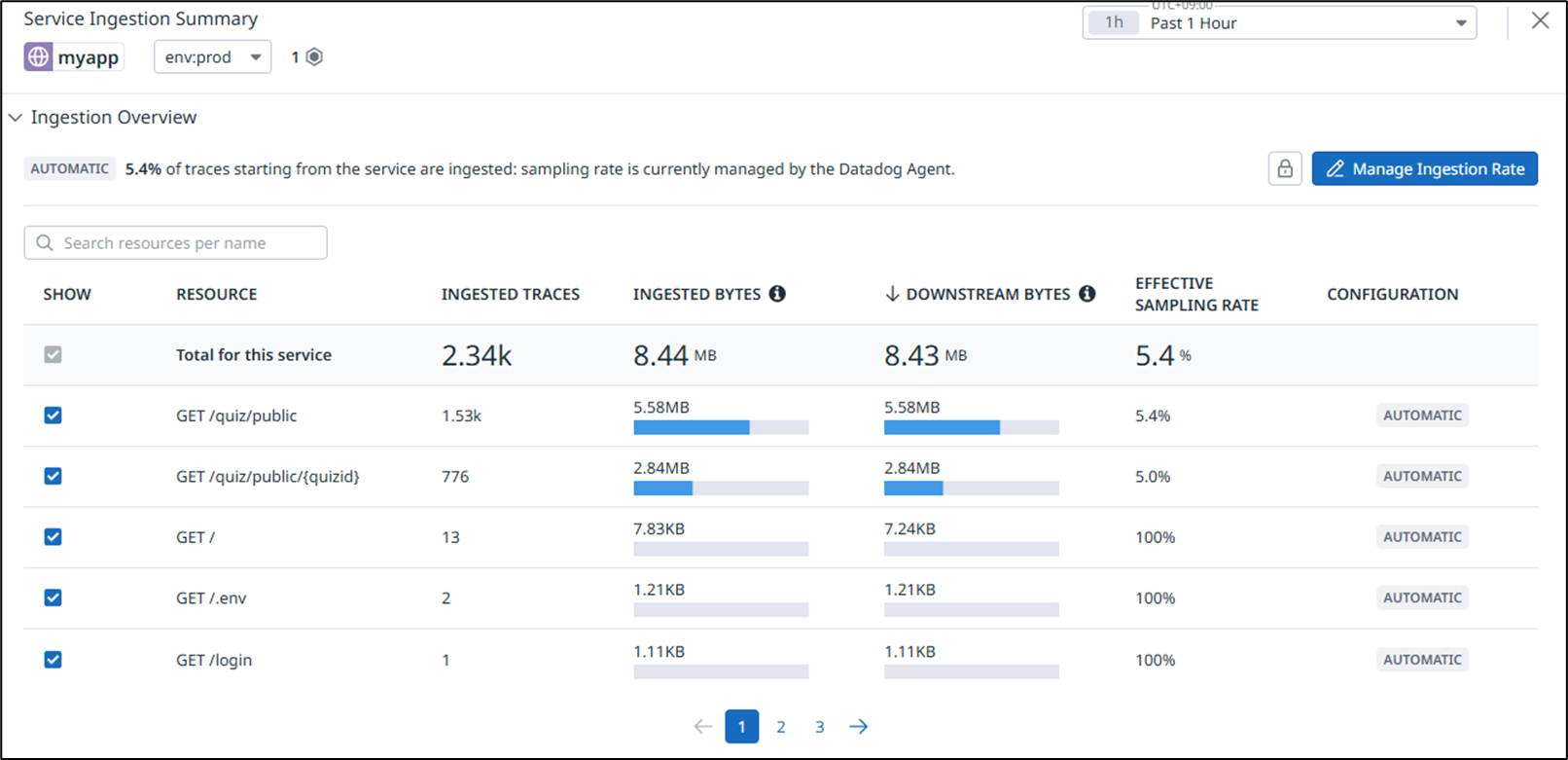
試しに “GET /quiz/public” に対するリクエストはトレース対象外に設定してみましょう。
以下の通り、監視対象サーバ側でdatadog.yamlの設定を変更します。
[root@quiz ~]# vi /etc/datadog-agent/datadog.yaml
apm_config:
filter_tags:
reject:
- "http.route:/quiz/public"
[root@quiz ~]# systemctl restart datadog-agent
[root@quiz ~]#
以下の通り、GET /quiz/public のデータ取り込みが発生しなくなったことを確認できます。
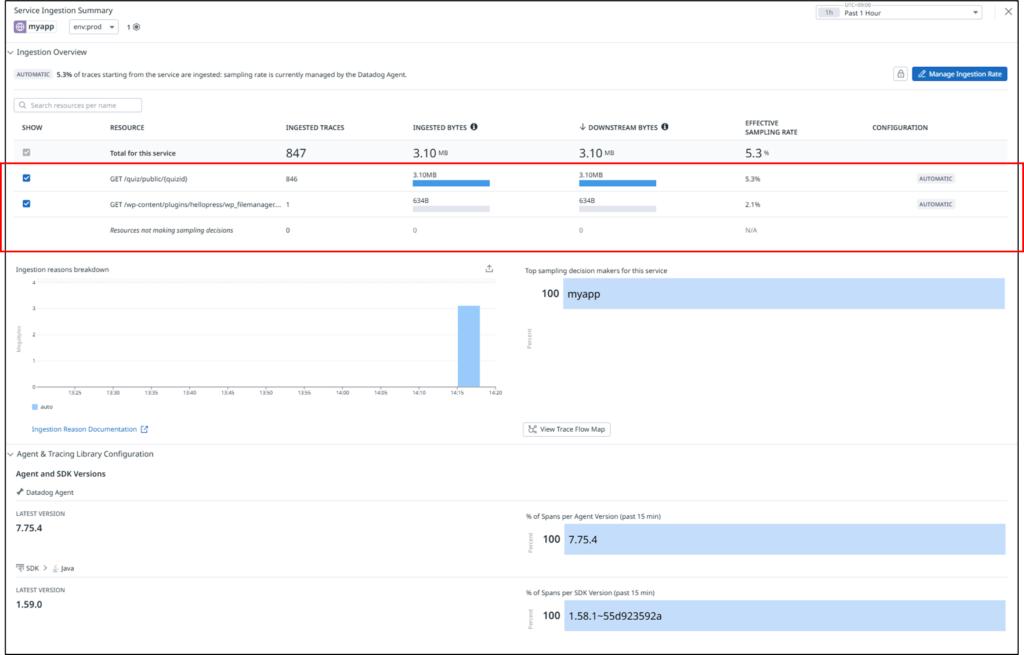
高カーディナリティなタグを避ける
APM トレースに付与するタグの設計にも注意が必要です。ユーザーIDやリクエストIDなど、リクエストごとに値が変わるタグを付与すると、データ量と内部処理コストが増大します。
- 静的・限定的な値のタグのみを使用する
- 動的に増え続ける値はタグにしない
といったルールを決めておくことが重要です。
ログのデータ転送量を抑える
Datadog において、ログは特にコストインパクトが大きいデータ種別です。アプリケーションログを無条件ですべて送信していると、転送量・保存量ともに急増しますので、ログ転送は必要最低限にすることを推奨します。
特に以下のようなログは、コスト増加の原因になりやすいです。
- 大量に出力される Info や DEBUG ログ
- リクエストごとに詳細なコンテキストを含むログ
Agent側でログをフィルタリングする
最も効果的な対策は、Datadog に送信する前にログを絞り込むこと です。
- ERROR や WARN レベルのみ送信する
- 特定のアプリケーションログのみ送信する
- パスやメッセージ内容でフィルタリングする
送信前に不要なログを捨てることで、ネットワーク転送量と Datadog 側の課金を同時に削減できます。
一例としてApacheのアクセスログ、エラーログにおいて、以下の設定をいれてみましょう。
① ERROR / WARN のみ送信する
②特定URLを除外(/health)
[root@quiz ~]# cat /etc/datadog-agent/conf.d/apache.d/conf.yaml
init_config:
instances:
- apache_status_url: https://127.0.0.1/server-status?auto
disable_ssl_validation: true
#Log section
logs:
# Access Log
- type: file
path: /var/log/httpd/access_log
source: apache
service: apache
sourcecategory: http_web_access
## Exclude health check setting
log_processing_rules:
- type: exclude_at_match
name: exclude_healthcheck
pattern: "/health"
# Error Log
- type: file
path: /var/log/httpd/error_log
source: apache
service: apache
sourcecategory: http_web_error
## Send ERROR/WARNING Message Setting
log_processing_rules:
- type: include_at_match
name: only_error_warn
pattern: "error|warn"
[root@quiz ~]#ログのサイズを意識する
JSON 形式のログを利用している場合、1行あたりのログサイズが大きくなりがちです。以下のような点を見直すだけでも、転送量削減につながります。
- 毎回同じ情報を冗長に出力していないか
- 不要に大きな配列やネスト構造を含めていないか
- 本当に必要なフィールドだけに絞れているか
メトリクスとカスタムメトリクスの見直し
カスタムメトリクスは気づかないうちに増える
Datadog では、カスタムメトリクスが課金対象となります。インテグレーションを有効にした結果、意図せず大量のメトリクスが送信されているケースも少なくありません。
- 実際にダッシュボードやアラートで使っているか
- 同じ意味のメトリクスが重複していないか
を定期的に見直すことが重要です。
高カーディナリティなタグ設計を避ける
メトリクスに付与されるタグの組み合わせ数が増えると、それだけ課金対象のメトリクス数も増えます。
- Pod 名やコンテナ ID
- UUID やセッション ID
といった動的な値は、可能な限りタグに含めない設計を心がけましょう。
コストを抑えるための運用ポイント
一度設定を見直して終わりではなく、継続的な運用が重要です。
- Datadog の Usage / Billing 画面を定期的に確認する
- 急増しているデータ種別を把握する
- 「なぜ増えたのか」を技術的に説明できる状態にする
- 開発環境・検証環境で本番同等の設定になっていないか
これにより、将来的なコスト増加にも早期に対応できます。
まとめ
Datadog のコスト増加の多くは、「気づかないうちに送信している大量のデータ」によって発生します。重要なのは、機能を止めることではなく、送信するデータの粒度と設計を見直すことです。
本記事で紹介したポイントを改めて整理すると、次のとおりです。
- Infrastructure の収集間隔を適切に設定する
- APM のサンプリングを調整する
- 不要なエンドポイントをトレース対象から除外する
- 高カーディナリティなタグ設計を避ける
- ログは送信前にフィルタリングする
- カスタムメトリクスの増加を定期的に確認する
Datadog は「すべてを送る」設計でも動作しますが、それは必ずしも最適とは限りません。可観測性を維持しながらコストを抑えるためには、必要なデータを、必要な粒度で、必要な期間だけ扱うという設計思想が重要です。特に本番環境だけでなく、開発・検証環境の設定も含めて定期的に見直すことで、将来的なコスト増加を防ぐことができます。
Datadog を長期的に活用していくためにも、一度「どのデータが本当に価値を生んでいるのか」を整理してみてください。


コメント