
はじめに
Linuxで構築しているシステムにおいて、「ディスク/ネットワーク I/O の応答が遅い」「I/O 待ちが頻発している」「サービスのレスポンスが低下している」というような症状は決して珍しくありません。I/O がボトルネックになると、CPU 使用率やメモリ使用率に余裕があったとしても、アプリケーションの遅延・タイムアウト・サービス停止などに直結します。
本記事では、I/O パフォーマンスに特化して、原因の調査から暫定対処、恒久対処までを体系的に解説します。
I/O パフォーマンス低下の影響
I/Oパフォーマンスの低下/滞留は、単にディスクの読み書きが遅いという問題にとどまらず、次のような影響を及ぼします。
- アプリケーションへの影響
- ファイル読み込み/書き込み待ちによるレスポンス遅延・タイムアウト
- 同時リクエスト数減少によるスループット低下
- バッチ処理の処理遅延/異常終了
- データベースへの影響
- トランザクション遅延
- ロック競合
- OSへの影響
- iowaitの増加、Load Average上昇
CPU 使用率が低くても、サーバ全体が“待ち”状態となりサーバダウンにつながる可能性あり - SSH 接続や管理操作が重くなる
- iowaitの増加、Load Average上昇
I/Oパフォーマンス低下時の調査手順
監視ツールにて iowait やレスポンスタイム遅延が閾値を超えたことを検知した場合、以下の手順で調査します。それぞれ説明します。
- I/Oパフォーマンス低下に関する概要情報を取得
- I/Oパフォーマンス低下を引き起こしているプロセスを特定
- 各種ログの確認
1. I/Oパフォーマンス低下に関する概要情報を取得
まずはLinuxサーバにおいて各種コマンドを実行することで、I/Oパフォーマンスに関する概要を把握します。
iostat コマンド
I/O 関連の詳細なリソース使用状況の概要を確認するには、iostatコマンドが最も有効です。
[root@appserver-dev ~]# iostat -x 1
Linux 5.14.0-570.22.1.el9_6.x86_64 (appserver-dev) 12/23/25 _x86_64_ (1 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.00 0.00 54.26 45.74 0.00 0.00
Device r/s rkB/s rrqm/s %rrqm r_await rareq-sz w/s wkB/s wrqm/s %wrqm w_await wareq-sz d/s dkB/s drqm/s %drqm d_await dareq-sz f/s f_await aqu-sz %util
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 377.00 386048.00 0.00 0.00 2.23 1024.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.84 84.20
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sda 0.00 0.00 0.00 0.00 0.00 0.00 754.00 386048.00 0.00 0.00 2.16 512.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 1.63 84.10RHEL9以降、iostatにて表示される項目がガラッと変わっていますので、内容を抑えておいてください。
サマリ情報(上部)
- %user:ユーザプログラムを実行していた時間
- %nice:nice値を変更したユーザプログラムの実行時間
- %system:カーネル(OS)が処理していた時間
- %iowait:I/O待ちでCPUが使えなかった時間
- %steal:仮想化環境で他VMにCPUを奪われた時間
- %idle:CPUが何も処理をしていなかった時間
デバイスごとの情報(下部)
- Device:ブロックデバイス名
dm-0、dm-1はDevice Mapperが作る仮想ブロックデバイス。dm-0がルートLV(Logical Volume)、dm-1がSwap LVであることが多いです。sdaが実際の物理ディスクになります。
<読み込み関連>
- r/s:1秒あたりの読み込み回数
- rkB/s:読み込みKB/秒
- rrqm/s:マージ(※)された読み込み ※マージとは、細かいI/Oを連続した大きなI/Oにまとめること。
- %rrqm:マージ率
- r_await:読み込み待ち時間(ms)
- rareq-sz:1回の読み込みサイズ(KB)
<書き込み関連>
- w/s 書き込み回数/秒
- wkB/s 書き込み量/秒
- wrqm/s マージ回数
- %wrqm マージ率
- w_await 書き込み待ち時間(ms)
- wareq-sz 1回の書き込みサイズ(KB)
<Discard関連>
- d/s:discard (※) 回数 ※ discard とは、OS がストレージに対して「このブロックは不要(解放済み)」と通知する I/O 処理
- dkB/s:discard量
- d_await:discard待ち
<Flush関連>
- f/s:flush (※) 回数 ※ flushとは、一時的にメモリにためている処理をディスクに書き込む処理。
- f_await:flush待ち時間
<その他>
- aqu-sz:平均I/Oキュー長
- %util:デバイス使用率。デバイスが I/O を処理している時間の割合を示す。
※ 各種値の解析方法
await、%utilを優先的に確認しましょう。以下のような考え方で事象を捉えられます。
- await:高、%util:高 → デバイスに対する I/O 要求が集中し、処理待ちが発生している(IOPS 飽和・キュー滞留の可能性)
- await:高、%util:低 → デバイス自体は高負荷ではないにもかかわらず I/O 完了まで時間がかかっている状態。ストレージパス、ネットワーク、仮想基盤側の遅延や障害の可能性がある。
- await:低、%util:高 → デバイスの利用率は高いが、並列処理能力により待ち時間は発生していない状態。現時点ではパフォーマンス影響はないが、負荷増加によりボトルネック化する可能性がある。
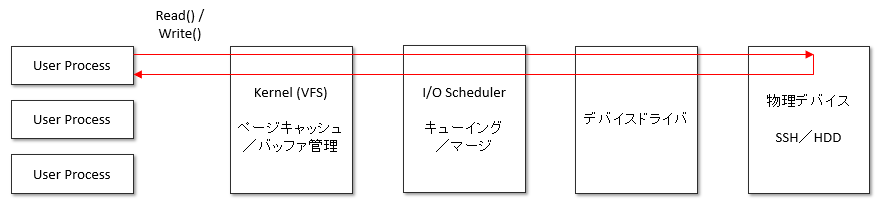
※ await
awaitとは I/O要求を発行してから、完了するまでに要した平均時間を示しています。下図の通り、UserプロセスからI/O要求を発行してから応答が返るまでの時間になります。
※ NVMe やマルチキューデバイスでは %util が 100% に近くても、必ずしも性能限界を示すとは限らない点に注意してください。aqu-sz や await と合わせて総合的に判断する必要があります。
top コマンド
top コマンドを実行することで、I/Oパフォーマンスに関する概要を把握することができます。
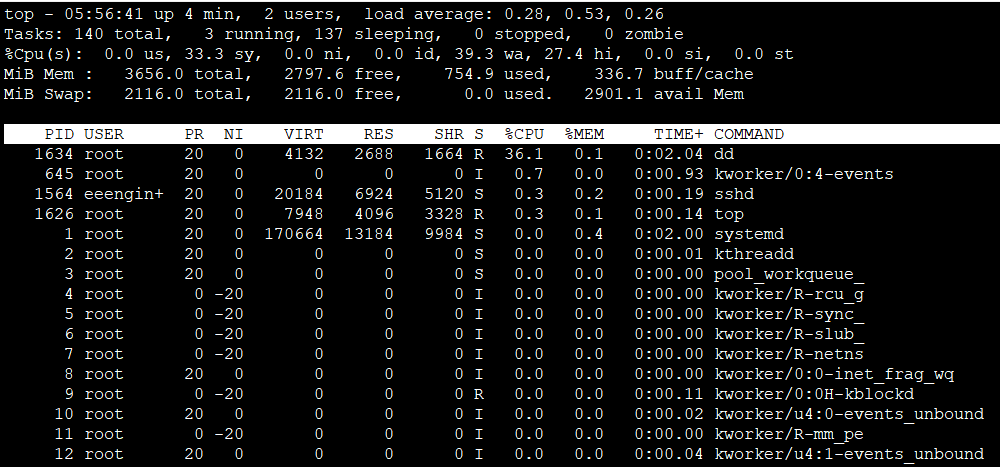
- wa:I/O待ちの時間の割合
vmstat コマンド
vmstatコマンドを実行することで、topコマンドと同様にI/O待ちの割合を確認することができます。
[root@appserver-dev ~]# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2832956 2948 342120 0 0 379 11123 289 586 2 8 89 1 0
0 0 0 2832956 2948 342120 0 0 0 0 101 193 0 2 98 0 0
0 0 0 2832956 2948 342120 0 0 0 0 82 179 0 1 99 0 0
0 1 0 2832956 2948 342120 0 0 0 27648 171 234 0 6 91 3 0
1 0 0 2832956 2948 342120 0 0 0 337923 875 590 0 54 1 45 0
2 0 0 2832956 2948 342120 0 0 0 333824 876 556 0 55 0 45 0
0 1 0 2832956 2948 342120 0 0 0 347136 878 611 0 54 0 46 0
2 0 0 2832956 2948 342120 0 0 0 351232 885 591 1 54 0 45 0
1 1 0 2832836 2948 342140 0 0 20 339968 923 748 0 56 0 44 0
0 1 0 2832724 2948 342364 0 0 192 344064 936 767 0 55 0 45 0
2 0 0 2832724 2948 342364 0 0 0 349184 885 587 0 54 0 46 0
1 0 0 2832724 2948 342364 0 0 0 351232 877 620 0 53 0 47 0
- wa:I/O待ちの時間の割合
- b:I/O待ちでブロックされているプロセス数
2. I/Oパフォーマンス低下の原因特定
I/Oパフォーマンスの低下状態が続いている場合は、原因を特定していきましょう。プロセスごとのI/O使用状況を把握するのが有効です。
iotopコマンド
iotopコマンドは、どのプロセスがI/Oを発生させているかをリアルタイムに可視化するコマンドです。–o オプションを付けることで、実際にI/Oが発生しているプロセスに絞って情報を出力することができます。
[root@quiz ~]# iotop -o
※ swap in/out が多い場合、I/O の原因が「メモリ不足」である可能性も考慮してください。
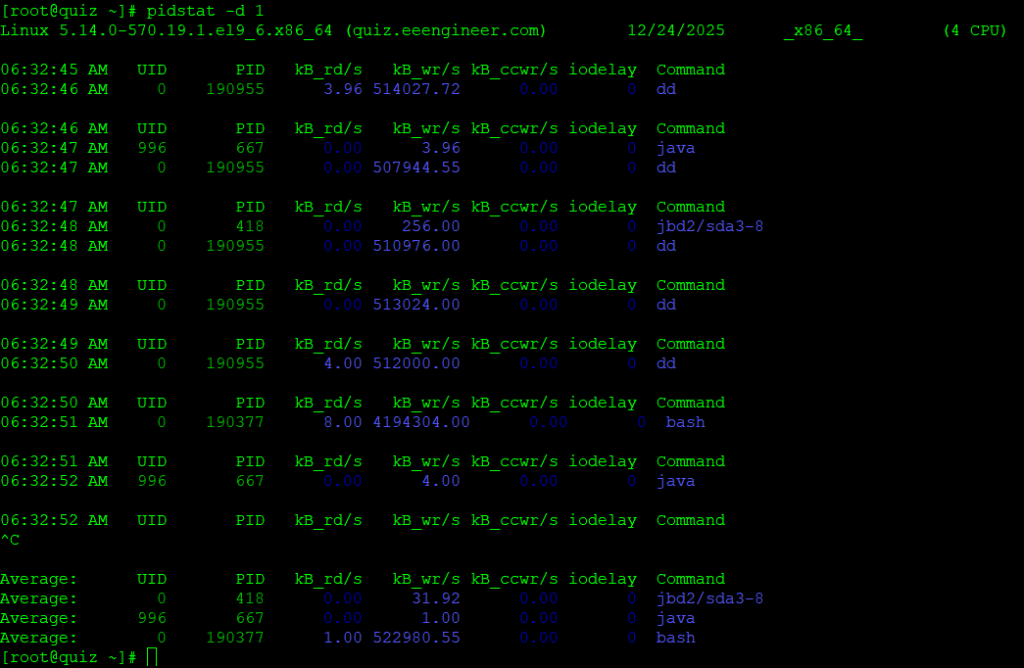
pidstatコマンド
pidstatは、プロセス性能を時系列で追うことができるコマンドになります。-d オプションを付けることで、I/O関連情報を取得することが可能です。下記は1秒ごとにpidstatを取得した結果になります。
3. 各種ログの確認
各種コマンドでI/Oパフォーマンス低下の状況を把握できたら、その後の原因特定のために各種ログを確認しましょう。
OSログ
Linux OS が出力している各種ログを確認しましょう。RHEL系のOSにおいて、I/O関連の不具合が発生していた際に出力されるログの一例を記載します。
- /var/log/messages
OS全般のログが記載されています。たとえば、下記のようなログが出力されます。
- kernel: blk_update_request: I/O error, dev nvme0n1, sector 1003749504
デバイスにてI/Oエラーが発生したことを示すログです。物理ディスク、コントローラの不具合や、接続の問題が疑われます。
“blk_update_request: I/O error, dev nbdN” follows “Connection timed out” on a third-party NBD device – Red Hat Customer Portal - kernel: end_request: I/O error, dev sdc, sector 0
OSがディスクにアクセスしようとしたが、失敗したことを表しています。こちらも物理ディスク、コントローラの不具合や、接続の問題が疑われます。
Why do I see I/O errors on a RHEL system using devices from an active/passive storage array? – Red Hat Customer Portal
- kernel: blk_update_request: I/O error, dev nvme0n1, sector 1003749504
DBサーバのログ
DBサーバのログに出力されている情報から、メモリ使用率の上昇要因を特定できる場合があります。ここでは一例として、PostgreSQLのログを確認する方法を紹介します。
- postgresql*.log
PostgreSQLデータベース内部で発生した各種動作や異常を記録するログファイルです。I/O関連エラーの一例を記載します。- cannot read block …: Input/output error
PostgreSQLがデータファイルのブロック読み込みに失敗した場合に出力されます。本エラーが発生した場合や、より低レイヤの問題を疑ってみましょう。
- cannot read block …: Input/output error
I/Oパフォーマンス低下時の暫定対処
I/O負荷が高い状態が続くと、システム全体のパフォーマンスに影響したり、場合によっては重要なプロセスがダウンする可能性があるので、早々に暫定対処を講じることを検討してください。原因次第ではありますが、OSレイヤの対処を中心に暫定対処例をご紹介します。
下記の通りI/Oの負荷が高まっている状況を例にとって、対処を実施してみましょう。
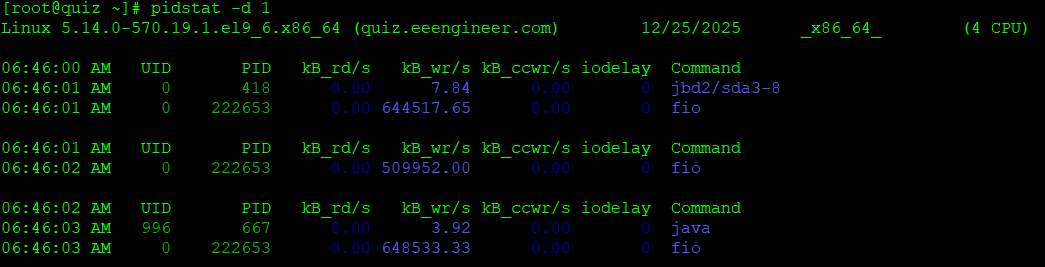
※ 試験的に”fio”コマンドを実行することでI/O負荷をかけています。
[root@quiz ~]# fio --name=write_test \
--filename=/tmp/io_test.img \
--size=4G \
--rw=write \
--bs=1M \
--direct=1 \
--ioengine=libaio \
--time_based \
--runtime=600 \
--iodepth=32
write_test: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=32
fio-3.35
Starting 1 process
Jobs: 1 (f=1): [W(1)][2.7%][w=510MiB/s][w=509 IOPS][eta 09m:44s]プロセス停止
I/Oパフォーマンス低下の原因となっているプロセスが特定できた場合、当該プロセスを停止するのが効果的です。ただし停止してもサービス提供に影響が出ないことを入念に確認したうえで、対処を実施してください。
killコマンド
killコマンドによりプロセスを停止してみましょう。killコマンドの引数にPIDを指定して実行してください。下記の通り、停止されたことを示すメッセージが標準出力に表示されます。
[root@quiz ~]# kill 222653
[root@quiz ~]#プロセスがハングしているなどの理由で、killコマンド(デフォルトは -15=SIGTERM)で停止できないケースがあります。その場合は、オプションkillコマンドに -9(SIGKILL)をつけて強制終了させましょう。
[root@quiz ~]# kill -9 222653
[root@quiz ~]#systemctl stopコマンド
今回の例では適用できませんが、問題があるサービスが特定できており停止しても問題ない場合は、killコマンドではなくsystemctl stopコマンドで停止するようにしましょう。
優先度制御
I/Oパフォーマンス低下の原因となっているプロセスが特定できたが、当プロセスを停止できない場合、優先度を制御することで他の処理への影響を抑える対処が考えられます。
I/O処理の優先度制御
“ionice”コマンドによってI/Oの優先度を低くすることができます。I/Oの優先度は3つのクラスで指定可能です。
| クラス | 値 | 説明 |
|---|---|---|
| real time | -c1 | 最優先の設定。基本的には使わない。 |
| best effort | -c2 | デフォルトのクラス。-n0~-n7でbest effortにおける優先度を指定することができる。-n0:優先度最高、-n7:優先度最低、-n4:デフォルトの優先度 |
| idle | -c3 | 優先度最低の設定。 |
下記の通り、優先度を変更することが可能です。
[root@quiz ~]# ionice -p 356398
none: prio 0
[root@quiz ~]#
[root@quiz ~]# ionice -c2 -n7 -p 356398
[root@quiz ~]# ionice -p 356398
best-effort: prio 7
[root@quiz ~]#デフォルトでは、none: prio 0と表示されます。こちらは、ベストエフォートクラスの優先度 -n4 となります。
CPU割り当ての優先度制御
直接的にI/Oを制御する方法ではありませんが、下記の通り”renice”コマンドでnice値を設定することで、CPU割り当ての優先を低くすることができます。
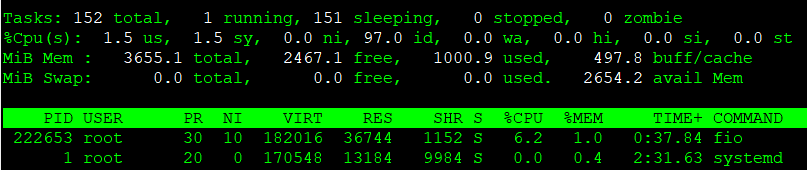
[root@quiz ~]# renice +10 -p 222653
222653 (process ID) old priority 0, new priority 10
[root@quiz ~]# topNIの項目が0から10に変更されており、優先度が下がっていることが確認できます。
リソース上限の設定
メモリ使用量が上昇しているプロセスを特定できたものの、当該プロセスを常時停止できない場合、フェイルセーフとしてI/Oの上限値を設定する方法が有効なケースがあります。一例として、postgresqlに対して上限値を設定する方法を記載します。
[root@quiz ~]# mkdir -p /etc/systemd/system/postgresql.service.d
[root@quiz ~]# vi /etc/systemd/system/postgresql.service.d/override.conf
[root@quiz ~]# cat /etc/systemd/system/postgresql.service.d/override.conf
[Service]
IOReadBandwidthMax=/dev/sdb 50M
IOWriteBandwidthMax=/dev/sdb 30M
[root@quiz ~]#
[root@quiz ~]# systemctl daemon-reexec
[root@quiz ~]# systemctl restart postgresql
[root@quiz ~]# systemctl show postgresql | grep -E "IOReadBandwidthMax|IOWriteBandwidthMax"
IOReadBandwidthMax=/dev/sdb 50000000
IOWriteBandwidthMax=/dev/sdb 30000000
[root@quiz ~]#I/Oパフォーマンス低下時の恒久対処
恒久対処とは、I/Oパフォーマンスが低下する根本原因を解消するための対応を指します。以下に代表的な例を示します。
- ストレージ設計の変更
- 複数ディスクにI/Oを分割する。ログ、DBデータ、WAL/REDOログなど。
- (オンプレ)HDDからSSD/NVMeへの
- (クラウド)IOPSが高いストレージへの変更
- RAID構成の変更(RAID5 → RAID10など)
- キャッシュ設計の修正
- アプリキャッシュ(Redis / Memcashed)の利用
- DBバッファサイズのチューニング
- fsync 多発の抑制
- Group Commit の有効化(commit ごとの fsyncを抑止し、fsyncを集約する)
- アプリケーションによる無駄な fsync() / flush() を抑止
- バッチ処理の設計改善
- 大量データの一括ロードを避ける。
- 処理の分割や実行タイミングの調整を行う。
- ログ出力設計の改善
- DEBUGログの出力抑止
- ログ圧縮およびログローテートの時間変更
まとめ
I/O パフォーマンス低下は、単なるディスク性能不足ではなく、アプリケーション設計、DB のトランザクション制御、ログ出力方針、さらにはストレージ構成や仮想基盤まで、複数の要因が重なって発生するケースがほとんどです。
重要なのは、事実ベースで切り分けることです。iostat・top・vmstat による全体把握から始め、iotop・pidstat によってI/O を発生させているプロセスを特定し、OS・ミドルウェア・DB ログを突き合わせることで、原因を段階的に絞り込むことができます。
また、障害対応においては
- 暫定対処として被害の拡大を防ぐ
- 恒久対処として I/O を発生させにくい設計へ見直す
という二段階の対応が不可欠です。fsync 多発の抑制、Group Commit の活用、キャッシュ設計の見直し、ストレージ構成の最適化などは、再発防止の観点で特に効果的です。
I/O は CPU やメモリと比べて可視化しづらく、後回しにされがちですが、本記事の手順を活用することで、場当たり的なチューニングではなく、再発しない I/O パフォーマンス設計を実現できるはずです。
本番環境でのトラブルシューティングや設計見直しの参考として、ぜひ役立ててください。


コメント