
はじめに
商用システムの運用において、LinuxサーバのCPU使用率が急上昇する問題は決して珍しいものではありません。CPU負荷は一時的なスパイクで済むこともあれば、アプリケーション障害やサービス停止へと発展し、ビジネスに直接影響を与えるケースもあります。
しかし、いざ高負荷を検知しても、
・どのプロセスが原因なのか?
・アプリケーション起因なのか、OS/ミドルウェア起因なのか?
・今すぐの暫定対処は?根本原因の特定方法は?
といったポイントを、短時間で判断し適切な対処を行うことは容易ではありません。
そこで本記事では、本番システムの安定運用を担うエンジニアの方に、確実に役立つ実践的なトラブルシューティング手法を解説していきます。
CPU高負荷の影響
CPU使用率は、システムがどれだけプロセスの計算処理にCPUを使っているかを示す指標です。高負荷状態が長時間続くと、以下のような影響が懸念されるため、早急な対処が必要です。
・アプリケーションのレスポンス遅延、タイムアウト
・バッチ処理の処理遅延、タイムアウト、異常終了
・SSH接続が重くなり、各種コマンドが実行できなくなる
・最悪の場合、サーバダウンにつながる
CPU高負荷時の調査手順
本番システムでは通常、監視ツールでCPU使用率が監視されています。CPU使用率が閾値を超えた場合の調査手順を解説します。
CPU使用率の概要情報を取得
まずはCPUに関して、OS全体としての使用状況を確認していきましょう。各種コマンドを説明します。
topコマンド
CPU使用率の概要を確認するには、topコマンドが有効です。topコマンドで以下の情報を確認できます。
[root@quiz ~]# top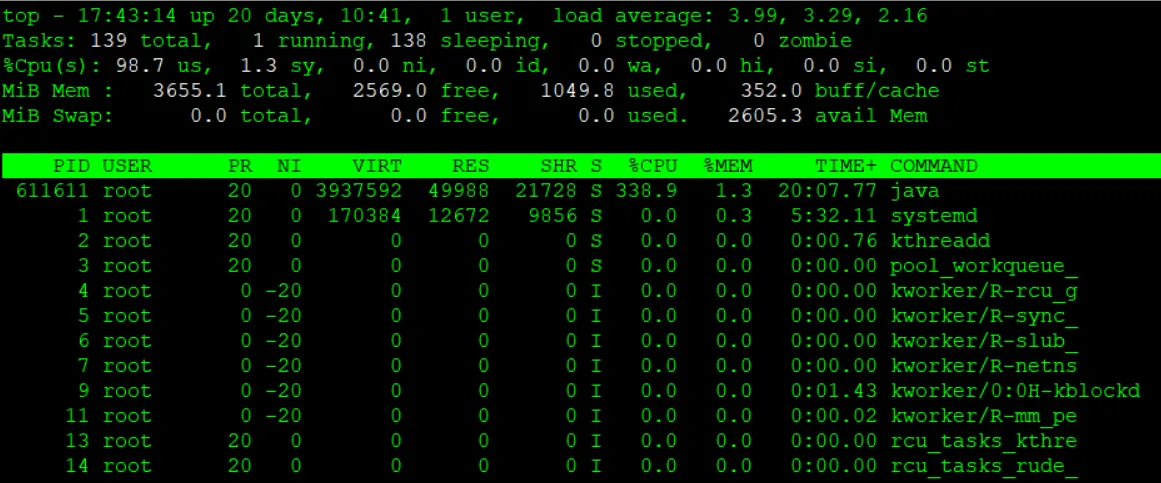
- load average
過去1分、5分、15分のシステム負荷を示しています。本例ではCPU論理コア数が4に対して、load averageが4に近い値となっているため、CPUに負荷がかかっている状態が見られます。
※論理コア数の確認方法
lscpu コマンドの cpu(s): の項目を確認するか、nproc コマンドで確認することができます。
あるいは、top コマンド実行後に「1」を押下することで、以下の通りCPUコア数および各コアの使用率を確認することができます。
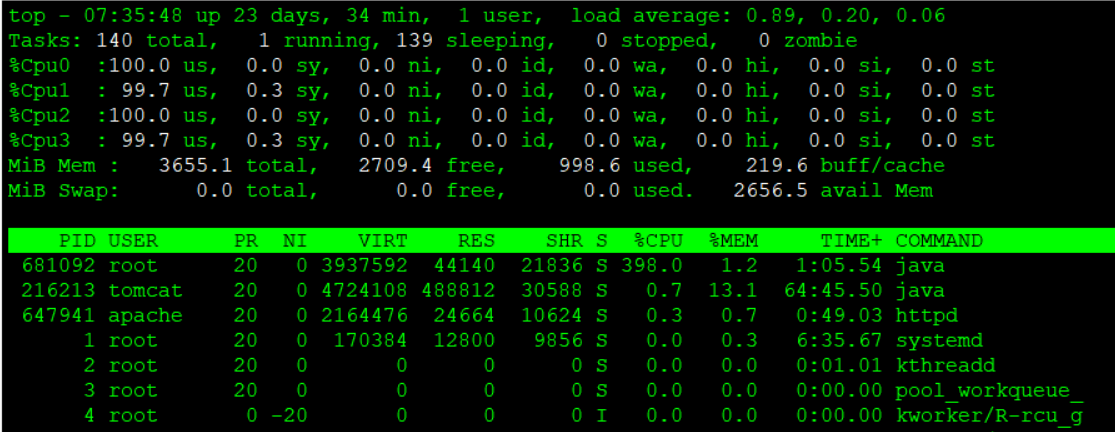
- %CPU (s)
CPU使用率を確認しましょう。各項目の意味は以下の通りです。- us:ユーザーCPU時間(user)
通常のユーザープロセスがCPUを使っている割合(カーネルモード以外)。 - sy:システムCPU時間(system)
カーネル(OS)プロセスがCPUを使っている割合 - ni:ユーザー優先度変更済み(nice)
nice 値が変更されたユーザープロセスがCPUを使っている割合 - id:アイドル(idle)
CPUが待機中の時間割合(何も処理していない)
まずはこの id の値を確認してください。
CPU使用率 = 100 – id となりますので、本例ではCPU使用率が100%に張り付いています。 - wa:I/O待ち(iowait)
ディスクやネットワークなどのI/O待ちでCPUが空いている時間 - hi:ハードウェア割り込み(hardware interrupt)
ハードウェア割り込み処理にCPUが使われた割合 - si:ソフトウェア割り込み(software interrupt)
ソフトウェア割り込み処理にCPUが使われた割合 - st:仮想化スティール時間(steal time)
仮想マシンで他のVMにリソースを奪われてCPUが待機している時間
- us:ユーザーCPU時間(user)
※CPU使用率は高くても、load averageが低いケースもあります。こういったケースはI/O待ちの状態が長くなっている可能性が高いので、I/O関連のリソースを確認しましょう。
CPU使用率上昇の原因特定
CPU使用率が高い状態が続いている場合は、原因を特定していきましょう。プロセスごと、あるいはスレッドごとのCPU使用状況を把握していきましょう。
topコマンド
topコマンドを実行すると、CPU使用率の高い順にプロセス情報が表示されます。通常よりリソース使用量が大きいプロセスがあれば、そのプロセスの詳細を確認し、原因を分析していきましょう。
各項目のCPUに関連する項目は以下の通りです。
- PID:プロセスID
プロセスごとの一意な識別番号 - USER:実行ユーザー
プロセスを実行しているユーザー名 - PR:優先度(Priority)
プロセスのスケジューリング優先度(数値が小さいほど優先度高) - NI:nice値
ユーザーが設定できるプロセス優先度補正値(-20〜19) - S:プロセス状態(State)
R=実行中, S=スリープ, D=割り込み不可スリープ, Z=ゾンビ, T=停止 - %CPU:CPU使用率
プロセスが消費しているCPU割合。スレッド単位での割合のため、複数コア環境では本例のように合計が100%を超えることもある。 - TIME+:累積CPU時間
プロセスがこれまでに消費したCPU時間(秒単位)。複数コアがある場合でも 各コアで実際に消費したCPU時間を合算した値になります。 - COMMAND:実行コマンド
プロセスの実行コマンド名またはパス
本例では PID 611611の java のCPU使用率が高い状況となっていますので、javaに関するCPU上昇の原因を追究していきましょう。
Javaアプリケーションやマルチスレッドプログラムを運用しているシステムにおいては、プロセス単位のCPU使用率では原因特定できないケースがあります。下記のように top コマンドに -H オプションをつけて、スレッド単位のリソース使用率を表示させることも可能です。
ここでは、先ほどの top コマンドにて特定したCPUを大量に使用しているjavaプロセスに対して、スレッドごとのリソース使用率を確認してみましょう。
[root@quiz ~]# top -H -p 611086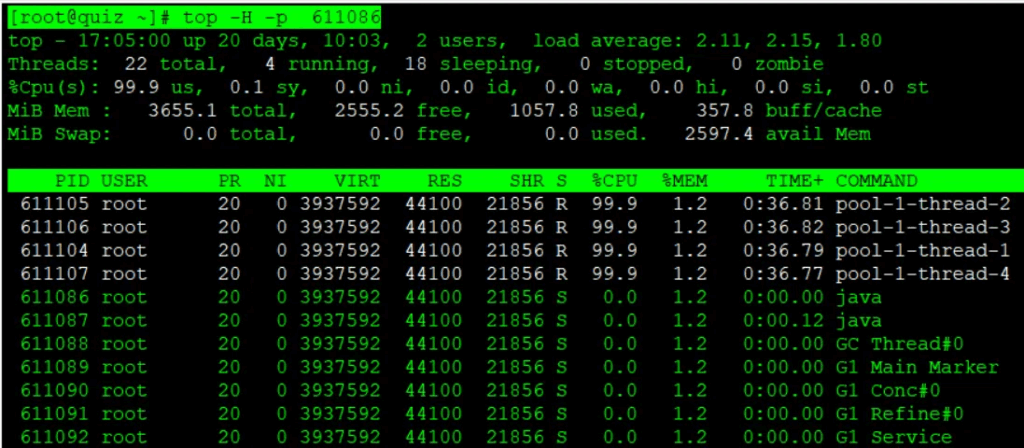
psコマンド
topコマンドとほとんど取得できる情報は変わりませんが、psコマンドでも同じようにCPU関連の情報を取得することができます。–sort -%cpu オプションをつけることで、CPUを大量に使用しているプロセスを特定することができます。
[root@quiz ~]# ps aux --sort -%cpu
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 611440 387 1.1 3937592 44148 pts/0 Sl+ 17:31 2:15 java -cp . CPUHog 4
root 611498 2.3 0.1 16628 6528 pts/1 S 17:32 0:00 su -
root 611462 1.6 0.2 20148 11136 ? Ss 17:32 0:00 sshd: eeengineer [priv]
root 611369 1.0 0.3 20148 11520 ? Ss 17:31 0:00 sshd: eeengineer [priv]
root 611411 0.7 0.1 16628 6528 pts/0 S 17:31 0:00 su -
tomcat 216213 0.3 12.9 4724108 484260 ? Sl Oct19 55:55 /opt/java/jdk-21.0.2/bin/java -Djava.util.logging.config.file=/
root 611475 0.3 0.2 19068 8192 ? Ss 17:32 0:00 /usr/lib/systemd/systemd-hostnamed
eeengin+ 611373 0.1 0.3 21604 11392 ? Ss 17:31 0:00 /usr/lib/systemd/systemd --userpidstatコマンド
pidstatコマンドを実行することで、プロセスごと、スレッドごとの情報を時系列で確認することができます。
まず、1秒ごとにpidstat情報を取得してみましょう。
[root@quiz ~]# pidstat 1
Linux 5.14.0-570.19.1.el9_6.x86_64 (quiz.eeengineer.com) 11/02/2025 _x86_64_ (4 CPU)
06:20:21 AM UID PID %usr %system %guest %wait %CPU CPU Command
06:20:22 AM 26 216415 0.00 0.98 0.00 0.00 0.98 2 postmaster
06:20:22 AM 0 707117 0.00 0.98 0.00 0.00 0.98 3 pidstat
06:20:22 AM UID PID %usr %system %guest %wait %CPU CPU Command
06:20:23 AM 996 216213 1.00 0.00 0.00 0.00 1.00 2 java
06:20:23 AM 0 706742 0.00 1.00 0.00 0.00 1.00 1 kworker/u16:0-events_unbound
06:20:23 AM 0 707117 1.00 0.00 0.00 0.00 1.00 3 pidstat
06:20:23 AM UID PID %usr %system %guest %wait %CPU CPU Command
06:20:24 AM 996 216213 0.00 1.00 0.00 0.00 1.00 2 java
06:20:24 AM 0 707117 0.00 1.00 0.00 0.00 1.00 3 pidstat特定のPIDに絞って情報取得することができます。
[root@quiz ~]# pidstat -p 707126 1
Linux 5.14.0-570.19.1.el9_6.x86_64 (quiz.eeengineer.com) 11/02/2025 _x86_64_ (4 CPU)
06:29:03 AM UID PID %usr %system %guest %wait %CPU CPU Command
06:29:04 AM 0 707126 397.00 0.00 0.00 0.00 397.00 0 java
06:29:05 AM 0 707126 400.00 0.00 0.00 0.00 400.00 0 java
06:29:06 AM 0 707126 399.00 1.00 0.00 0.00 400.00 0 java
06:29:07 AM 0 707126 399.00 0.00 0.00 0.00 399.00 0 java
06:29:08 AM 0 707126 400.00 0.00 0.00 0.00 400.00 0 java
06:29:09 AM 0 707126 399.00 0.00 0.00 0.00 399.00 0 javaスレッドごとの情報取得ができます。
[root@quiz ~]# pidstat -t 1
Linux 5.14.0-570.19.1.el9_6.x86_64 (quiz.eeengineer.com) 11/02/2025 _x86_64_ (4 CPU)
06:30:03 AM UID TGID TID %usr %system %guest %wait %CPU CPU Command
06:30:05 AM 48 699715 - 0.00 0.85 0.00 0.00 0.85 1 httpd
06:30:05 AM 0 707126 - 359.32 0.00 0.00 0.00 359.32 0 java
06:30:05 AM 0 - 707133 0.85 0.00 0.00 0.00 0.85 0 |__VM Periodic Tas
06:30:05 AM 0 - 707144 89.83 0.00 0.00 0.85 89.83 0 |__pool-1-thread-1
06:30:05 AM 0 - 707145 87.29 0.00 0.00 3.39 87.29 2 |__pool-1-thread-2
06:30:05 AM 0 - 707146 90.68 0.85 0.00 0.00 91.53 1 |__pool-1-thread-3
06:30:05 AM 0 - 707147 89.83 0.00 0.00 0.85 89.83 3 |__pool-1-thread-4
06:30:05 AM 0 707280 - 0.85 1.69 0.00 1.69 2.54 2 pidstat
06:30:05 AM 0 - 707280 0.85 1.69 0.00 1.69 2.54 2 |__pidstat
06:30:05 AM UID TGID TID %usr %system %guest %wait %CPU CPU Command
06:30:06 AM 0 707126 - 397.00 0.00 0.00 0.00 397.00 0 java
06:30:06 AM 0 - 707144 100.00 0.00 0.00 0.00 100.00 0 |__pool-1-thread-1
06:30:06 AM 0 - 707145 96.00 0.00 0.00 4.00 96.00 2 |__pool-1-thread-2
06:30:06 AM 0 - 707146 100.00 0.00 0.00 0.00 100.00 1 |__pool-1-thread-3
06:30:06 AM 0 - 707147 101.00 0.00 0.00 0.00 101.00 3 |__pool-1-thread-4
06:30:06 AM 0 707280 - 3.00 2.00 0.00 3.00 5.00 2 pidstat
06:30:06 AM 0 - 707280 3.00 2.00 0.00 3.00 5.00 2 |__pidstat各種ログの確認
topコマンドなどでリソース使用状況を把握するのが先決ですが、その後の原因特定のために各種ログを確認しましょう。
OSログ
Linux OS が出力している各種ログを確認しましょう。RHEL系のログを記載します。
- /var/log/messages
OS全般のログが記載されています。たとえば、下記のようなログが出力されます。- INFO: task : blocked for more than 120 seconds
あるプロセスが120秒以上、実行待ち状態でブロックし続けていることを示しています。何らかの理由で、CPUを使えていないとか、I/O待ちになっていることが想定されます。 - kernel: soft lockup – CPU#1 stuck for 22s! [process:1234]
CPUがソフトロックアップ状態になっていることを示しています。CPUがタスクを切り替えできず、システムがフリーズ気味になっていることが想定されます。 - kernel: Watchdog detected hard LOCKUP on cpu 2
CPUがハードロックアップ状態になっていることを示しています。割り込み処理にも応答できず、CPUが完全にフリーズしていることが想定されます。
- INFO: task : blocked for more than 120 seconds
※systemd journalを使用している場合は、journalctl -xe などで確認して下さい。
- /var/log/cron
cron処理の実行に関するログになります。直接的にCPU使用率上昇の原因は特定できませんが、cron処理が実行されている時間を確認することで、間接的に原因特定できる可能性があります。
Webサーバのログ
Webサーバのログを確認することで、リクエスト量やエラーが急増していないかを確認してみましょう。ログの出力ディレクトリは設計によって変わるので、自システムの設計にあわせて読み替えて下さい。
- アクセスログ
/var/log/httpd/access_log(Apache)、/var/log/nginx/access.log(Nginx)を確認し、レコード件数が通常よりも多くなっていないか、特定のURLに偏っていないか、などを確認しましょう。最近ではDDoS攻撃が多くなってきているので、システム側に問題がなくてもリソース使用率が急上昇し、システム閉塞につながるトラブルが起きることもあります。 - エラーログ
/var/log/httpd/error_log(Apache)、/var/log/nginx/error.log(Nginx)にエラーが発生しているかどうかを確認しましょう。大量にエラーが出力されていた場合は、CPU使用率上昇の原因の可能性があります。
APサーバのログ
APサーバのログに出力されている情報から、CPU使用率上昇の原因を特定できることがあります。ここでは、tomcatを例にとってみてみましょう。
- catalina.out
Tomcatの標準出力、標準エラーが出力されるログになります。Javaのスタックトレースが出ていたり、同じログが大量に出ていることがあれば、CPU上昇の原因である可能性がありますので、確認してみてください。 - gc.log
GC(ガベージコレクション)が要因で、CPU使用率が上昇しているケースが想定されます。GCに関するログを確認することで、GCの回数が通常より多くなっていたり、GC処理時間が長くなっていたら要確認です。
※tomcatにおけるgc.logの有効化
tomcatにおいて、GCに関するログはデフォルトでは出力されません。下記の設定を追加して、gc.logが出力されるようにしておくことを推奨します。
[root@quiz ~]# vi /opt/tomcat/bin/setenv.sh
[root@quiz ~]# cat /opt/tomcat/bin/setenv.sh
~~Omitted~~
## GC Log Setting
-Xlog:gc*,safepoint:file=$CATALINA_BASE/logs/gc.log:time,level,tags:filecount=5,filesize=10M"
[root@quiz ~]#
[root@quiz ~]# systemctl restart tomcat
[root@quiz ~]#
以下のようにGCに関するログが出力されていれば成功です。以下の例では正常な範囲でマイナーGCが発生していることが確認できます。
[2025-11-03T21:57:11.276+0900][info][safepoint ] Safepoint "ICBufferFull", Time since last: 894905347 ns, Reaching safepoint: 7277 ns, Cleanup: 159379 ns, At safepoint: 3260 ns, Total: 169916 ns
[2025-11-03T21:57:11.352+0900][info][gc,start ] GC(0) Pause Young (Normal) (G1 Evacuation Pause)
[2025-11-03T21:57:11.353+0900][info][gc,task ] GC(0) Using 2 workers of 4 for evacuation
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Pre Evacuate Collection Set: 0.3ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Merge Heap Roots: 0.2ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Evacuate Collection Set: 31.4ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Post Evacuate Collection Set: 2.0ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Other: 0.7ms
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Eden regions: 13->0(14)
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Survivor regions: 0->2(2)
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Old regions: 2->4
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Humongous regions: 0->0
[2025-11-03T21:57:11.389+0900][info][gc,metaspace] GC(0) Metaspace: 6598K(6848K)->6598K(6848K) NonClass: 5909K(6016K)->5909K(6016K) Class: 689K(832K)->689K(832K)
[2025-11-03T21:57:11.389+0900][info][gc ] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 14M->4M(60M) 37.236ms
[2025-11-03T21:57:11.389+0900][info][gc,cpu ] GC(0) User=0.03s Sys=0.04s Real=0.04sDBサーバのログ
DBサーバのログに出力されている情報から、CPU使用率の上昇要因を特定できる場合があります。ここでは一例として、PostgreSQLのログを確認する方法を紹介します。
- postgresql*.log
PostgreSQLデータベース内部で発生した各種動作や異常を記録するログファイルです。CPU使用率が上昇している場合、このログに関連する事象が出力されていないか確認してみてください。
例えば、データベースの性能トラブルの中で、最も一般的な事象の一つがスロークエリの発生です。スロークエリとは、クエリの実行に長時間を要する処理のことで、実行回数が少なくても、状況によってはデータベース全体の性能に影響を及ぼす可能性があります。
ここではPostgreSQLを例に、ログ出力の例を示します。あらかじめ設定した処理時間の閾値を超えた場合、以下のように処理時間と実行されたSQLがログに記録されます。
[root@quiz ~]# tail /var/lib/pgsql/data/log/postgresql-Fri.log
2025-11-07 10:48:20.143 JST [859967] LOG: duration: 2024.725 ms statement: SELECT pg_sleep(2);
[root@quiz ~]#
※スロークエリを検知するには、postgresql.conf に以下の設定を追加または変更します。
この例では、1,000ms(1秒)を超えた処理をログ出力対象としています。
[root@quiz ~]# vi /var/lib/pgsql/data/postgresql.conf
[root@quiz ~]# grep log_min_duration_statement /var/lib/pgsql/data/postgresql.conf
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
log_min_duration_statement = 1000 # Log SQL statements that take longer than 1 second※Oracle Databaseでスロークエリを解析する場合は、AWR(Automatic Workload Repository)レポート や ASH(Active Session History) を使用するのが一般的です。
これらのレポートから、実行時間が長いSQLやCPU消費の高いSQLを特定できます。
CPU使用率上昇時の暫定対処
CPU使用率上昇が続くとシステム全体のパフォーマンスに影響する可能性があるので、何かしらの対処を講じることを検討してください。原因次第ではありますが、OSレイヤの対処を中心に一例をご紹介します。
下記の通り、bashプロセスがCPU1コアを占有している状況を例にとって、対処を実施してみましょう。ちなみにtopコマンド実行後に「1」を押下することで、CPUコアごとの使用率が確認できます。
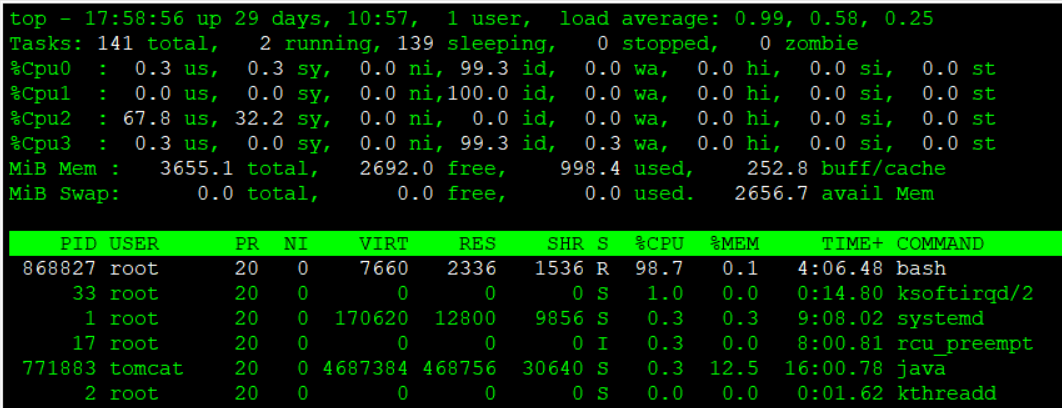
※CPU1コア占有状態とするコマンドを試験的に実行しています。
[root@quiz ~]# while :; do echo $((22**22)) > /dev/null; done &
[1] 870406
[root@quiz ~]#プロセス停止
CPU使用率上昇の原因となっているプロセスが特定できた場合、当該プロセスを停止するのが効果的です。ただし停止してもサービス提供に影響が出ないことを入念に確認したうえで、対処を実施してください。
killコマンド
killコマンドによりプロセスを停止してみましょう。killコマンドの引数にPIDを指定して実行して下さい。下記の通り、停止されたことを示すメッセージが標準出力に表示されます。
[root@quiz ~]# kill 868827
[root@quiz ~]#
[1]+ Terminated while :; do
echo $((22**22)) > /dev/null;
done
[root@quiz ~]#プロセスがハングしているなどの理由で、killコマンド(デフォルトは -15=SIGTERM)で停止できないケースがあります。その場合は、オプションkillコマンドに -9(SIGKILL)をつけて強制終了させましょう。
[root@quiz ~]# kill -9 868827
[root@quiz ~]#
[1]+ Killed while :; do
echo $((22**22)) > /dev/null;
done
[root@quiz ~]#systemctl stopコマンド
今回の例では適用できませんが、問題があるサービスが特定できており停止しても問題ない場合は、killコマンドではなくsystemctl stopコマンドで停止するようにしましょう。
優先度制御
CPU使用率上昇の原因となっているプロセスが特定できたが当プロセスを停止できない場合、当プロセスに対するCPU割り当ての優先度を制御することで、他の処理に影響が及ばないようにする対処が考えられます。
下記の通り、reniceコマンドでnice値を設定することで、優先を低くすることができます。
[root@quiz ~]# renice 10 -p 887442
887442 (process ID) old priority 0, new priority 10
[root@quiz ~]#
[root@quiz ~]# top
top - 11:06:45 up 30 days, 4:05, 1 user, load average: 0.66, 0.20, 0.07
Tasks: 142 total, 2 running, 140 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 9.4 sy, 17.2 ni, 73.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 3655.1 total, 2717.3 free, 977.7 used, 243.7 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2677.4 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
887442 root 30 10 7556 2320 1536 R 100.0 0.1 1:05.95 bash
27 root 20 0 0 0 0 S 6.2 0.0 0:26.96 ksoftirqd/1
1 root 20 0 170620 12800 9856 S 0.0 0.3 9:25.39 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:01.69 kthreadd
ただし、CPU使用率は下がらないため、早急に恒久対処の適用を検討してください。
リソース上限の設定
CPU使用率が上昇しているプロセスを特定できたが、、当該プロセスを停止できず、かつ優先度を制御しても他のプロセスに影響が出る場合は、CPU使用率の上限を設定する方法が有効な場合があります。
以下の通り、cpulimitコマンドを使用して特定プロセスのCPU使用率の上限を指定できます。bashプロセスのCPU使用率が50%程度に抑えられていることが確認できます。
[root@quiz ~]# cpulimit -p 887537 -l 50 &
[2] 887664
[root@quiz ~]# Process 887537 found
[root@quiz ~]#
[root@quiz ~]# top
top - 11:18:20 up 30 days, 4:16, 2 users, load average: 0.73, 0.86, 0.56
Tasks: 148 total, 2 running, 146 sleeping, 0 stopped, 0 zombie
%Cpu(s): 8.6 us, 4.2 sy, 0.0 ni, 87.0 id, 0.0 wa, 0.0 hi, 0.2 si, 0.0 st
MiB Mem : 3655.1 total, 2490.1 free, 1024.5 used, 455.5 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 2630.6 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
887537 root 20 0 7556 2336 1536 R 50.2 0.1 3:59.92 bash
17 root 20 0 0 0 0 I 0.7 0.0 8:58.15 rcu_preempt
33 root 20 0 0 0 0 S 0.3 0.0 0:42.48 ksoftirqd/2
568 root 16 -4 19084 4252 1536 S 0.3 0.1 4:45.13 auditd
771883 tomcat 20 0 4687384 467480 30640 S 0.3 12.5 18:32.28 java
887590 root 9 -11 2652 1664 1536 S 0.3 0.0 0:00.14 cpulimit
ただし、CPUリソースを制限すると処理時間が延び、サービスに影響が出る可能性があります。そのため、恒久的な対処方法の適用を早急に検討してください。
CPUコア数の拡張
物理サーバでは対応が難しい場合がありますが、仮想サーバであれば論理 CPU コア数の拡張は比較的容易に実施できます。CPU 使用率が継続的に高く、スレッド並列性が確保できているワークロードであれば、有効な対処となる可能性があります。
ただし、I/O wait やロック競合、シングルスレッド処理がボトルネックとなっている場合、CPU コア数を増やしても効果が限定的なため、原因を切り分けた上で選択肢のひとつとして検討してください。
CPU使用率上昇時の恒久対処
恒久対処とは、CPU 使用率が上昇する根本原因を解消するための対応を指します。以下に代表的な例を示します。
- アプリケーションの修正
高負荷な計算処理や無限ループを修正し、アプリケーションをリリースする。 - データベース処理の最適化
スロークエリや処理負荷の高いクエリを見直し、インデックスの追加や SQL の改善を行う。 - 流量制限の導入
突発的なリクエスト増加や DDoS 攻撃に備え、リクエスト数を制限することで、過剰な CPU 消費を発生させない設計とする。 - バッチ処理の設計改善
リソース負荷が低い時間帯に処理を実行する、またはバッチ処理を分割することで、CPU負荷が集中しないように設計を改善する。 - CPU使用に関する設定変更
CPU 使用率が常時高く、処理の並列性が確保できている場合には、論理 CPU の追加などを検討する。
まとめ
本記事では、LinuxサーバにおけるCPU使用率の上昇に対する調査手順と対処方法を体系的に解説しました。ポイントを整理すると以下の通りです。
- CPU高負荷の影響を理解する
高負荷状態が長時間続くと、アプリケーションの遅延、バッチ処理の異常、SSH接続不能、最悪の場合はサーバダウンなどのリスクがあるため、早急な対応が重要です。 - 原因の特定手順を把握する
- top、ps、pidstatコマンドを用いて、プロセス単位・スレッド単位でCPU使用率を確認する。
- OSログやWeb/AP/DBログを確認し、CPU負荷の発生タイミングや要因を特定する。
- 暫定対処でシステムの安定性を確保する
- 不要なプロセスを停止する (kill、systemctl stop)
- 優先度を下げて他プロセスへの影響を抑える (renice)
- CPU使用率の上限を設定して負荷を制御する (cpulimit)
- 仮想環境であればCPUコア数を一時的に増加させる
- 恒久対処で根本原因を解消する
- アプリケーションやSQLの最適化
- バッチ処理の分割や実行タイミングの調整
- 流量制限やDDoS対策の導入
- ハードウェア構成の見直し
CPU使用率の上昇は、単なる一時的な現象ではなく、システム全体の安定性やサービス品質に直結する問題です。本記事で紹介した調査手順と対処方法を理解し、暫定対応と恒久対応を組み合わせることで、商用システムの安定運用をより確実なものとしていただければ幸いです。


コメント