
ITシステムがブラックボックス化している現代においてインフラエンジニアの需要は縮小していくという人もいますが、私は必ずしもそうではないと考えています。特にパフォーマンス分野のエンジニアは今後も絶対になくならない職種のひとつだと言ってよいでしょう。なぜならシステムがいくらブラックボックス化したとしても各システムの特性に適した難易度のパフォーマンスチューニングが必要不可欠だからです。しかしその分難易度も高く、どういった設計をしたらよいのか一般的なベストプラクティスがあまりないように思いましたので、パフォーマンス設計のベストプラクティスをまとめてご紹介しようと思います。今回はシステム構成およびハードウェアに関するパフォーマンス設計についてご紹介しますのでぜひご参照ください。
1. はじめに
今回のシリーズでは、LinuxシステムにおけるWeb3層のオンラインシステムを想定したパフォーマンスベストプラクティスをご紹介させていただきます。システムパフォーマンスを向上させるには、システムを構成するあらゆる要素を考慮する必要があります。たとえばミドルウェアのチューニングが完璧でもネットワークの通信速度が出ていなくて処理遅延につながることもあります。したがってパフォーマンスエンジニアはあらゆる要素に対する知見をもって対応する必要があります。一般的にシステムを動作させるために必要な要素を下図に記載します。
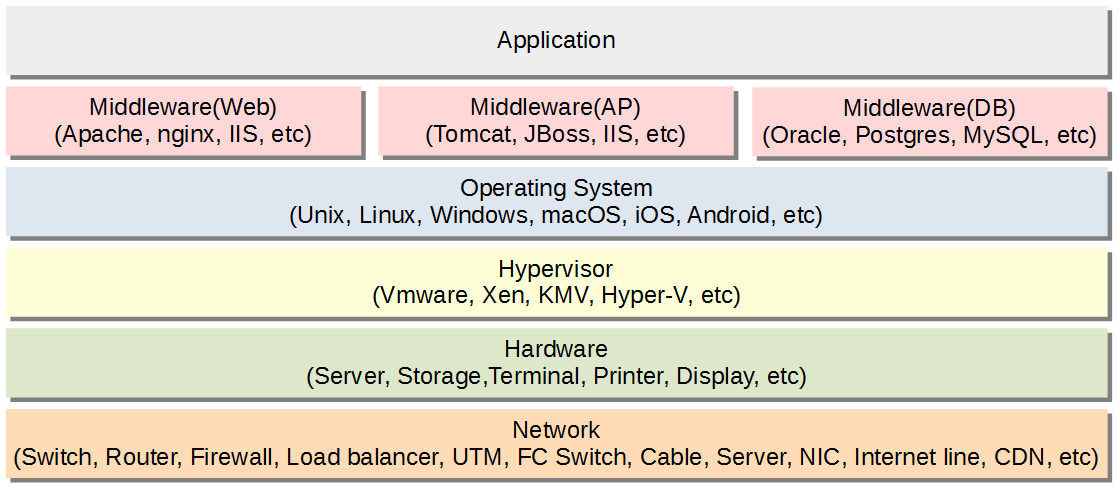
Webシステムに必要なハードウェアは、サーバ、ストレージ、端末、NW機器、ロードバランサ、ファイアウォール等が挙げられます。ハードウェアのスペック、CPU/メモリ等の付属製品およびハードウェアの構成を考える必要がありますのでご紹介させていただきます。特にオンプレミス環境の構築をする際にはここのハードウェア構成の設計が誤ってしまうと後々取り返しのつかない結果となりますので、慎重に検討するようにしていただければと思います。
2. システム構成
まずはハードウェア選定の前にシステム構成を検討する必要があります。物理構成および論理構成の例をご提示させていただきます。
2.1 物理構成図
概略図とはなりますが、Webシステムを構成するための物理構成図例を記載いたします。ネットワーク機器、サーバ、ストレージで構成しています。ネットワーク機器については他の機器に置き換わることもあるかと思いますので、要件に応じて選定して下さい。例えばUTMを記載してますが高価な製品であることが多いので、安価なファイアウォールを導入するという選択肢もあります。
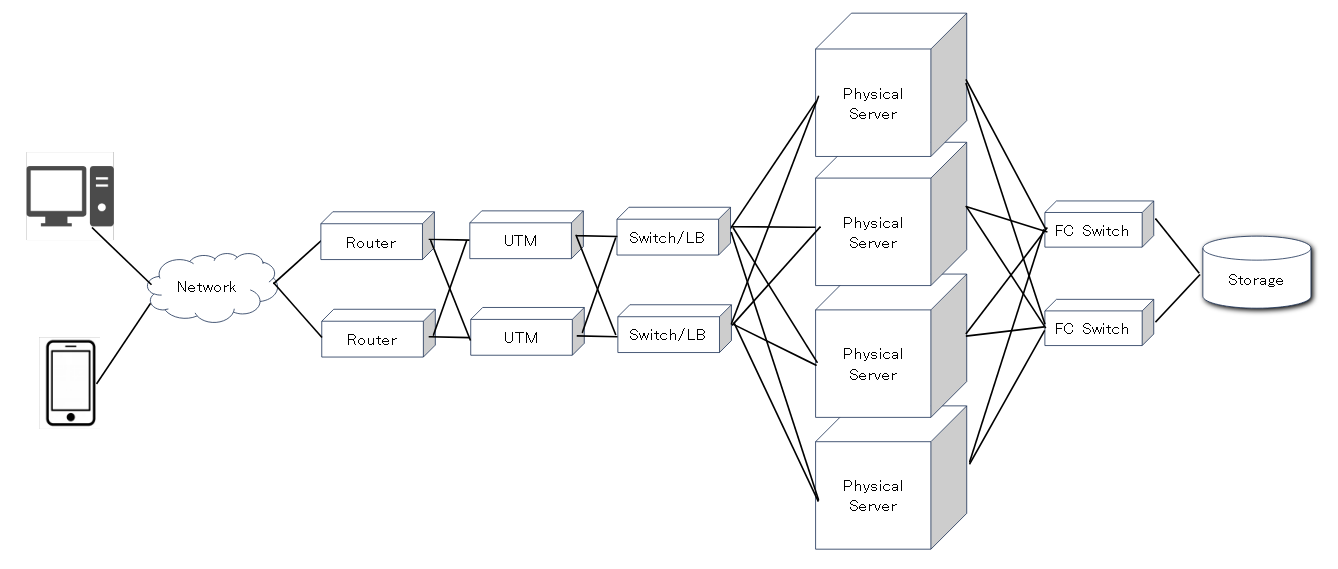
物理構成の検討においてパフォーマンス観点で気を付けるポイントを記載します。
□1台故障時のパフォーマンスを考慮
物理機器は必ず故障するものなので、故障した際でも必要とされているパフォーマンスが出るシステム構成にする必要があります。NW機器およびサーバ機器については必ず冗長構成を組むようにしてください。
2.2 論議構成図
続いて論理構成図例を記載します。WebサーバをUTMとFWで挟んだ構成にすることでDMZをつくっています。その後ろはAPレイヤ、DBレイヤとなっており一般的なWeb3層システムの構成図となっています。WebサーバとAPサーバは仮想サーバとして構築していますが、DBサーバは物理サーバとしています。仮想サーバおよび物理サーバのOSおよびデータを共有ストレージに格納しており、SANブートで起動するようなシステムを想定しています。
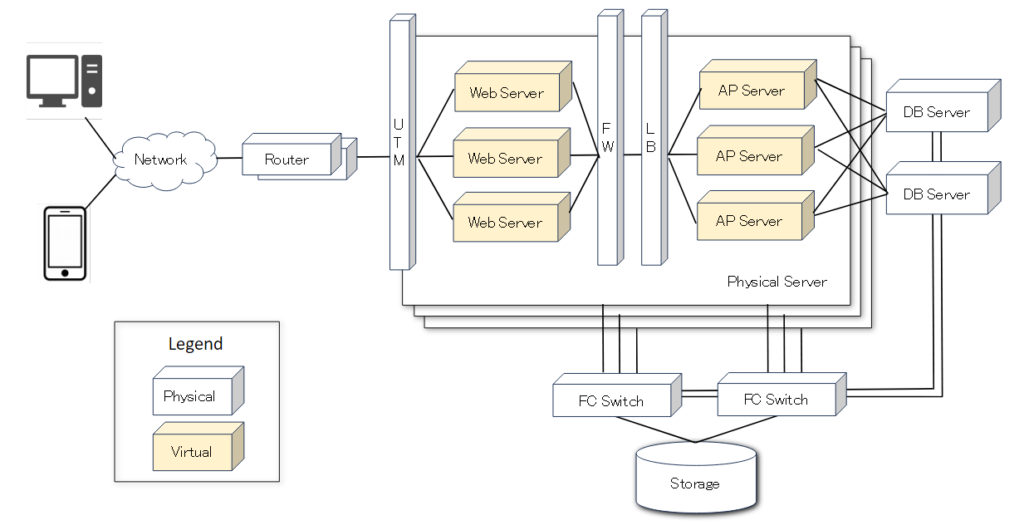
論理構成の検討においてパフォーマンス観点で気を付けるポイントを記載します。
□1台故障時のパフォーマンスを考慮
物理機器と同様で、仮想サーバについても故障してダウンしてしまうことがありますので、故障した際でも必要とされているパフォーマンスが出るシステム構成にする必要があります。一例としてWebサーバおよびAPサーバは3台、DBサーバは2台で冗長構成をとる構成としていますが、要件に合わせて各レイヤで必要なサーバ台数を設計するようにして下さい。1台故障して縮退運転になったとしても要件定義で決められたスループットを処理できるような設計が必要です。
□重要な機器はリソース共有しない
システムの根幹であるDBサーバがパフォーマンスのボトルネックになることが多いので単独の物理サーバで構成しています。仮想化により他のサーバとリソースを共有してしまうと、トラブル発生時や想定以上の負荷が来た際にDBサーバのパフォーマンスに影響してしまう可能性があります。予算に余裕がある場合は個別に物理サーバに構築することをお勧めします。
3. ハードウェア要素のパフォーマンス設計
3.1 サーバ機器選定・サイジング
サーバの筐体の選定だけでなく、CPU、メモリ、ディスクなど検討しなければならないリソース要素は多々あります。必要なリソース量を見積もる方法は主に2つあります。
①類似システムの情報を用いた見積り(全般)
類似の要件を処理しているシステムに関する情報が入手できるのであれば、それをもとにサイジングするのが最も有効なやり方です。サーバや各種部品のスペックが全く同じではないので100点の見積りはできないですが、ある程度妥当な見積りができるはずです。
②ベンチマーク手法に基づいた見積り(CPU)
CPUについてはベンチマークを参考にした見積りをすることが一般的です。SPECと呼ばれるベンチマークのデータが公開されていまして、いろいろ値がありますがSPECint2017のBase Resultの情報をもとに見積るのが一般的です。下記にサンプル情報を記載します。
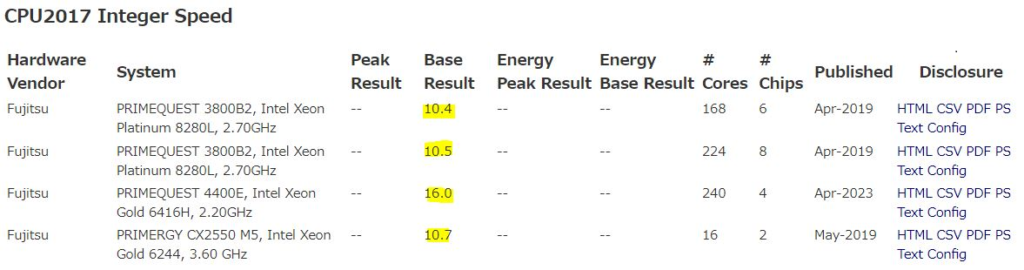
<SPECのサイト>
https://www.spec.org/cpu2017/results/
基本的にCPU使用率は負荷量に比例しますので、負荷量の増分と新旧機器のSPECint2017の比率を用いることで必要なコア数を算出します。しかしこの計算はあくまで想定する見積りであり外れることがありますので、プロトタイプ検証環境を構築して精緻化することを推奨します。
③積み上げによる見積り
<メモリ>
サーバにインストールするソフトウェア製品に必要なメモリを積み上げていくことである程度の見積りをすることは可能です。ただしメモリ使用量は負荷量に比例するわけではなく精緻な見積りは難しいので余裕を持ったサイジングを推奨します。CPUコア数の場合はライセンス費用に関わるので簡単に増やす決断をすることは難しいですが、メモリについてはライセンス費用に影響しないですし、そこまで高価な部品でもないです。積み上げで見積もったメモリサイズの2倍くらいで余裕を持った設計にしておくことをお勧めします。
<ディスク>
ソフトウェアインストールに必要な容量、保存が必要な業務データ総量、ログ出力量などを考慮してディスクサイズを見積もる必要があります。また、VMwareなどの仮想化技術を採用している場合に仮想サーバのバックアップを取得するディスクについても忘れずに見積もっておくようにしましょう。
3.2 サーバ機器のパフォーマンス設計
□ハイパースレッディングの有効化
ハイパースレッディングとはひとつのプロセッサコアを疑似的に2つに見せかける技術であり、1コアで並行して2つのスレッドを実行することができます。CPUの待ち時間を有効に使うだけなので単純に2コアと同等になるわけではなく処理性能の向上は20%~30%程度であることが一般的です。ただし、下記のような場合は性能劣化する可能性もあるので注意が必要です。
・計算効率が極端に高い
・スレッドの負荷バランスが悪い
・並行処理によるボトルネックが発生
UEFI 設定あるいはBIOS設定から変更することが可能ですので適用を検討してみて下さい。
3.3 ストレージ機器選定
・あらかじめ各サーバのIOPSを計測する、あるいは見積もったうえで、必要なIOPSを処理できるストレージを選定するのが原則となります。ただしIOPSは使用条件によって値が変わるため、カタログに記載されているIOPSを鵜呑みにしないよう注意して下さい。
・DB更新などの高い性能要件があるデータ対しては、フラッシュストレージ(SSD)の導入を検討しましょう。ただしSSDだと書き換え回数に限度があるので、長年使い続ける想定の場合は交換作業を見込んでおく必要があります。一方でバックアップ等の性能が必要のないデータに対しては安価なHDDを採用するという選択肢もあると思います。
・キャッシュディスクによる性能向上は重要な要素なので、適切なキャッシュディスクの容量を選択するようにしましょう。
3.4 ストレージ機器のパフォーマンス設計
□RAID設計
RAIDとはRedundant Array of Inexpensive Disksの略で、複数のディスクをまとめてひとつのディスクのように扱うことができる技術です。性能観点で言うと主にストライピングという技術を適用することによって、書き込み速度および読み込み速度を向上させることができます。RAIDにはいろいろ種類がありまして、非機能要件によって最適な方式を選定することが必要です。以下に設定例を記載します。
・データベースの業務データなどのオンライン処理にて更新・参照するデータについてはRAID10を適用することで高い性能および信頼性を担保する
・バックアップや過去のログデータなどのオンライン処理に関係のないデータについてはRAID5を適用することで性能よりもコスト削減を重視する
ひとつのRAIDグループを構成するために必要なディスクの推奨本数が決まっているので、データの総量が多い場合は複数のRAIDグループを作成するのが一般的です。それぞれのRAIDグループに対する書き込みを見積り、なるべく各RAIDグループに対する処理の負荷が同程度になるように設計しましょう。また、I/Oの特性としてDB書き込みであればランダム、バックアップであればシーケンシャルで書き込みが行われるのですが、こういったI/O特性が異なるデータについては異なるRAIDグループに分けて配置することを推奨します。
まとめ
システム構成およびハードウェアに関するパフォーマンス設計のご紹介は以上となります。ここまで読んでいただきありがとうございました。他の要素についての記事も書いているのでよかったら合わせて見てもらえると嬉しいです。
Webシステムのパフォーマンス設計に関するベストプラクティス(ネットワーク要素編)
参考文献
Best Practices for System Performance

インテル® ハイパースレッディング・テクノロジーのパフォーマンスに関する考察

企業向けストレージに必要な条件とは?



コメント