
はじめに
本番環境でLinuxサーバのメモリ使用率が急上昇する問題は決して稀ではありません。メモリが逼迫すると、スワップ発生、I/O遅延、アプリケーションの応答遅延、最悪の場合にはサービス停止という重大な影響を及ぼすことがあります。
しかし、いざメモリ使用率の上昇を検知しても、以下のような疑問が生じます。
- どのプロセス/スレッドがメモリを大量に使っているのか
- アプリケーション起因か、OS/ミドルウェア起因か
- 今すぐできる暫定対処は?根本原因特定のプロセスは?
といった課題は、迅速に判断・対応するのが簡単ではありません。
そこで本記事では、商用システムにおいて確実に役立つ「メモリ使用率が高い」状況時の実践的なトラブルシューティング手法を整理します。
メモリ使用率が高いことによる影響
メモリ使用率が高まると、以下のような影響が懸念されます。
- メモリ枯渇 → スワップ発生 → I/O待ちが増加 → アプリケーションレスポンスが遅延
- 長時間この状態が続くとサービス停止につながる
- バッチ処理や時間のかかる処理が遅れるまたはタイムアウト
- OOM(Out of Memory)Killer 発動や再起動・クラッシュの可能性
- SSH接続/管理コンソールの遅延、操作不能になる
メモリ使用率は、単に「%が高い」というだけではなく、「空きメモリが急速に減っている」「スワップの使用が増えている」「バッファ/キャッシュが異常に大きい」などの変化も重要です。
メモリ使用率が高い時の調査手順
監視ツールでメモリ使用量やスワップ使用量が閾値を超えた場合、以下の手順で調査します。それぞれ説明します。
- メモリ使用率に関する概要情報を取得
- メモリ使用率を上昇させているプロセスを特定
- 各種ログの確認
- メモリダンプの解析
1. メモリ使用率に関する概要情報を取得
まずはLinuxサーバにおいて各種コマンドを実行することで、メモリ使用状況の概要を把握します。
free コマンド
実メモリ使用率を即座に確認できるのは free コマンドです。
[root@quiz ~]# free
total used free shared buff/cache available
Mem: 3742864 1258272 2516480 93872 269220 2484592
Swap: 0 0 0
[root@quiz ~]#- total
物理メモリの総量。/proc/meminfo の MemTotal の値となります。 - used
キャッシュ込みの使用中メモリ量となります。解放できるキャッシュも含んでいるため、実際のメモリ使用量を正確に把握する項目としては適切ではありません。 - free
完全に未使用なメモリ - shared
複数プロセスで共有されているメモリ - buff/cache
再利用可能なバッファキャッシュ、ページキャッシュの総量。必要に応じて解放される。 - available
即座に使えるメモリの総量となります。最重要項目となりますので、取り急ぎ本値を確認して下さい。
下記の通り、実メモリ使用率を確認することができます。
実メモリ使用率(%) = ( total – available ) / total × 100
= ( 3742864 – 2484592 ) / 3742864 × 100
≒ 33.6 %
meminfoの確認
メモリ使用率に関する情報を最も正確に取得するためには、meminfo ファイルの内容を確認するのが良いです。下記の通り、free コマンドと比較して様々なリソースに関する情報を取得することが可能です。
[root@quiz ~]# cat /proc/meminfo
MemTotal: 3742864 kB
MemFree: 1599236 kB
MemAvailable: 2420176 kB
Buffers: 14228 kB
Cached: 1111208 kB
SwapCached: 0 kB
Active: 1030672 kB
Inactive: 925768 kB
Active(anon): 924940 kB
Inactive(anon): 52 kB
Active(file): 105732 kB
Inactive(file): 925716 kB
Unevictable: 16 kB
Mlocked: 16 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Zswap: 0 kB
Zswapped: 0 kB
~~Truncated~~
[root@quiz ~]#
top コマンド
top コマンドを実行することでも、メモリ使用量に関する概要を把握することができます。
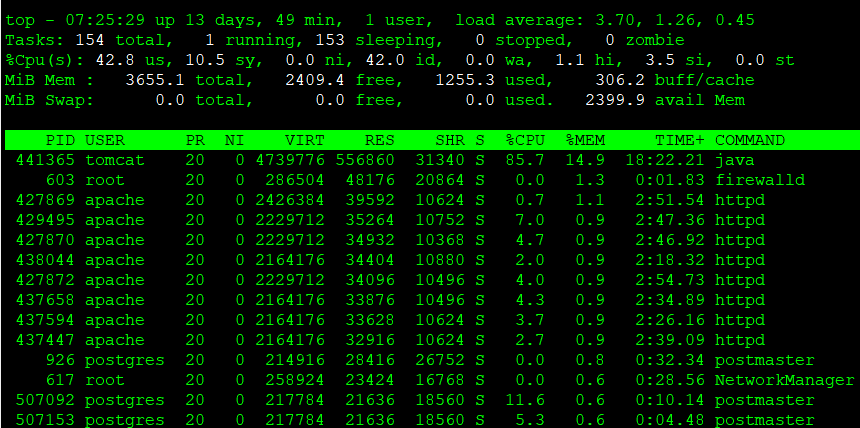
- MiB Mem:
- total:物理メモリの総量
- free:何も使用されていない完全な空きメモリ
- used:使用中のメモリ(free、buff/cacheを除いた値)
- buff/cache:OS がキャッシュやバッファとして使用しているメモリ(必要に応じて解放可能)
- MiB Swap:
- total:スワップ領域全体
- free:空いているスワップ
- used:使用されているスワップ量
- avail mem:実際にアプリケーションが利用できるメモリ量
vmstat コマンド
vmstatコマンドを実行することで、スワップイン、スワップアウトが発生しているかどうかを確認することができます。
[root@quiz ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2416156 6696 276192 0 0 7 6 1 4 1 0 99 0 0
[root@quiz ~]#- si:スワップイン(swap → RAM)/ 秒
- so:スワップアウト(RAM → swap)/ 秒
メモリ使用率上昇の原因特定
メモリ使用率が高い状態が続いている場合は、原因を特定していきましょう。プロセスごとのメモリ使用状況を把握するのが有効です。
topコマンド
top コマンド実行後に”M”を押下することで、メモリ使用率が高い順にプロセスを表示させることができます。通常よりメモリ使用量がプロセスが存在している場合は、そのプロセスの状態をさらに分析していきましょう。
top コマンドにおける%MEMは下記の値となります。
%MEM = RES / Total Physical Memory ×100
参考:Ubuntu Manpage: top – display Linux processes
ps コマンド
topコマンドとほとんど取得できる情報は変わりませんが、psコマンドでも同じようにメモリ関連の情報を取得することができます。–sort=-%mem オプションをつけることで、メモリを大量に使用しているプロセスを特定することができます。
[root@quiz ~]# ps aux --sort=-%mem
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
tomcat 441365 2.8 15.9 4725384 598056 ? Sl Dec07 200:50 /opt/java/jdk-21.0.2/bin/java -Djava.util.logging.config.file=/opt/tomcat/conf/logging.properties -D
root 603 0.0 1.2 286504 48176 ? Ssl Nov26 0:01 /usr/bin/python3 -s /usr/sbin/firewalld --nofork --nopid
apache 427869 0.1 1.1 2426384 42236 ? Sl Dec06 10:54 /usr/sbin/httpd -DFOREGROUND
apache 427870 0.1 1.0 2229712 37876 ? Sl Dec06 10:39 /usr/sbin/httpd -DFOREGROUND
apache 429495 0.1 1.0 2229712 37824 ? Sl Dec07 10:45 /usr/sbin/httpd -DFOREGROUND
apache 437594 0.1 1.0 2164176 37596 ? Sl Dec07 10:40 /usr/sbin/httpd -DFOREGROUND
apache 427872 0.1 1.0 2229712 37552 ? Sl Dec06 10:40 /usr/sbin/httpd -DFOREGROUND
apache 438044 0.1 1.0 2164176 37476 ? Sl Dec07 10:01 /usr/sbin/httpd -DFOREGROUND
apache 437658 0.1 0.9 2164176 37204 ? Sl Dec07 10:55 /usr/sbin/httpd -DFOREGROUND
apache 437447 0.1 0.9 2164176 35476 ? Sl Dec07 10:34 /usr/sbin/httpd -DFOREGROUND
apache 509665 0.1 0.8 2164176 30752 ? Sl Dec09 6:15 /usr/sbin/httpd -DFOREGROUND
postgres 926 0.0 0.7 214916 28416 ? Ss Nov26 0:46 /usr/bin/postmaster -D /var/lib/pgsql/data
root 617 0.0 0.6 258924 23424 ? Ssl Nov26 0:34 /usr/sbin/NetworkManager --no-daemon
root 100329 0.1 0.5 336892 19008 ? Sl Nov26 24:40 fluent-bit -c /etc/fluent-bit/fluent-bit.conf -vv
root 921 0.0 0.4 312188 18128 ? Ssl Nov26 6:30 /usr/sbin/rsyslogd -n
root 643 0.0 0.4 23432 15628 ? Ss Nov26 1:50 /usr/sbin/httpd -DFOREGROUND
root 1 0.0 0.3 171704 14208 ? Ss Nov26 6:37 /usr/lib/systemd/systemd --switched-root --system --deserialize 31
pmap
pmapコマンドを実行することで、各アドレスごとにどんなメモリが割り当てられているかが表示されます。メモリ使用量が多い領域、あるいはリークしている領域を特定する際に実行して下さい。
[root@quiz ~]# pmap -x 441365 | sort -k3 -nr
total kB 4725388 597448 566076
00000000c6e00000 167936 167936 167936 rw--- [ anon ]
00007f4627eff000 45168 44092 44092 rw--- [ anon ]
00007f4594000000 35500 35496 35496 rw--- [ anon ]
00007f4584000000 28384 28384 28384 rw--- [ anon ]
00007f4610a00000 23488 23488 23488 rwx-- [ anon ]
00007f46184c8000 21952 21924 21924 rwx-- [ anon ]
00007f45b19f0000 21504 21504 21504 rw--- [ anon ]
00007f4588000000 17652 17648 17648 rw--- [ anon ]
00007f462de00000 19528 15744 0 r-x-- libjvm.so
00007f45b09f0000 15360 15360 15360 rw--- [ anon ]
00007f45a8000000 14172 13140 13140 rw--- [ anon ]
00007f45b3000000 12952 12932 10788 rw--- classes.jsa
00007f4550000000 12532 12532 12532 rw--- [ anon ]
00007f45f4000000 11836 11836 11836 rw--- [ anon ]
6列目に以下のような情報が表示されます。
- anon:プロセスが動的に確保したメモリ(malloc/newなど)
- [heap]:ヒープ領域。プログラムが実行中に確保する。
- [stack]:スタック領域。関数呼び出しやローカル変数を保存する領域。
- xx.so:共有ライブラリが使用している領域。
smem
smem コマンドを実行することで、各プロセスに対する共有メモリの正確な割り当てを確認することができます。ps や top で確認できる RSS だけでは共有メモリの値が分からないので、正確な値を把握したい場合は本コマンドを実行してみてください。
[root@quiz ~]# smem -r | sort -k4 -nr
PID User Command Swap USS PSS RSS
99936 root -bash 0 928 1418 4496
99935 root su - 0 1156 1471 6628
99933 root sudo su - 0 1432 2225 8648
926 postgres /usr/bin/postmaster -D /var 0 8588 12006 29272
921 root /usr/sbin/rsyslogd -n 0 13528 14988 19688
917 root /sbin/agetty -o -p -- \u -- 0 180 217 1856
662 root /usr/sbin/crond -n 0 936 1005 3628
647 root sshd: /usr/sbin/sshd -D [li 0 1316 1811 9268
643 root /usr/sbin/httpd -DFOREGROUN 0 968 2048 15776
626792 root sort -k4 -nr 0 620 709 3392
626791 root /usr/bin/python3 /usr/bin/s 0 10060 11650 15424
620337 root sshd: [accepted] 0 1288 1819 9312
617 root /usr/sbin/NetworkManager -- 0 11184 13726 23972
611 chrony /usr/sbin/chronyd -F 2 0 1220 1440 4160
611991 postgres postgres: postgres quiz 127 0 1700 3236 21920
611791 postgres postgres: postgres quiz 127 0 1700 3236 21920
611784 postgres postgres: postgres quiz 127 0 1688 3224 21908
611737 postgres postgres: postgres quiz 127 0 1688 3224 21908
611725 postgres postgres: postgres quiz 127 0 1688 3224 21908
611714 postgres postgres: postgres quiz 127 0 1684 3220 21904
- USS(Unique Set Size):プロセスが専有しているメモリ
- PSS(Proportional Set Size):共有メモリをプロセス数で按分した値であり、正確な使用量を表している。
- RSS(Resident Set Size):ps、top と同じ物理メモリ使用量
slabtop
slabtopコマンドを実行することで、Linuxカーネル内部のメモリキャッシュに関する情報を取得することができます。アプリケーション側に問題がない場合には、Linuxカーネルレイヤの調査をしてみてください。
[root@quiz ~]# slabtop -o -s c
Active / Total Objects (% used) : 255087 / 274077 (93.1%)
Active / Total Slabs (% used) : 7926 / 7926 (100.0%)
Active / Total Caches (% used) : 159 / 232 (68.5%)
Active / Total Size (% used) : 57275.80K / 61190.98K (93.6%)
Minimum / Average / Maximum Object : 0.01K / 0.22K / 8.00K
OBJS ACTIVE USE OBJ SIZE SLABS OBJ/SLAB CACHE SIZE NAME
13704 13087 95% 0.66K 571 24 9136K inode_cache
804 798 99% 7.19K 201 4 6432K task_struct
18846 18553 98% 0.21K 1047 18 4188K vm_area_struct
19110 17066 89% 0.19K 910 21 3640K dentry
22240 22174 99% 0.12K 695 32 2780K kernfs_node_cache
2640 2323 87% 1.00K 165 16 2640K kmalloc-1k
2002 2002 100% 1.19K 77 26 2464K ext4_inode_cache
3668 3195 87% 0.57K 131 28 2096K radix_tree_node
424 412 97% 4.00K 53 8 1696K kmalloc-4k
15873 15873 100% 0.10K 407 39 1628K buffer_head
7245 6846 94% 0.19K 345 21 1380K kmalloc-192
2368 1632 68% 0.50K 148 16 1184K kmalloc-512
576 549 95% 2.00K 36 16 1152K kmalloc-2k
352 305 86% 2.69K 32 11 1024K TCPv6
348 330 94% 2.50K 29 12 928K TCP
1045 1001 95% 0.80K 55 19 880K shmem_inode_cache
935 817 87% 0.94K 55 17 880K sock_inode_cache
19380 18702 96% 0.04K 190 102 760K vma_lock
23680 16940 71% 0.03K 185 128 740K lsm_inode_cache
92 73 79% 8.00K 23 4 736K kmalloc-8k
11584 11354 98% 0.06K 181 64 724K anon_vma_chain
6786 6636 97% 0.10K 174 39 696K anon_vma
各種ログの確認
各種コマンドでリソース使用状況を把握できたら、その後の原因特定のために各種ログを確認しましょう。
OSログ
Linux OS が出力している各種ログを確認しましょう。RHEL系のOSにおいて、メモリ関連のトラブルが発生していた際に出力されるログの一例を記載します。
- /var/log/messages
OS全般のログが記載されています。たとえば、下記のようなログが出力されます。
OOM killerが発生した場合、シスログにメッセージが送信されます。何のプロセスがKillされていたか分かります。
kernel: Out of memory: Kill process 1234 (java) score 987 or sacrifice child
kernel: Killed process 1234 (java) total-vm:20480000kB, anon-rss:10240000kB, file-rss:5000kB, shmem-rss:0kBpage allocation failure のメッセージが出ていたら、連続するページを確保できていないということを意味します。これはメモリの断片化が進んでいる可能性を示していますので、/proc/buddyinfoを参照し、断片化の状態を確認してください。
kernel: page allocation failure: order:10, mode:0x20
kernel: Node 0 DMA32: 1234kB unavailable
kernel: Mem-Info:
kernel: active_anon:12345 inactive_anon:6789 active_file:123456 inactive_file:789012SLABメモリの割り当てに関するメッセージが出ていたら、カーネルによるメモリリークを疑ってみてください。
kernel: SLUB: Unable to allocate 4096 bytes
kernel: kmalloc-64: active objects exceed threshold
kernel: Out of memory: kmalloc-1024 allocation failureWebサーバのログ
Webサーバのログを確認することで、リクエスト量やエラーが急増していないかを確認してみましょう。ログの出力ディレクトリは設計によって変わるので、自システムの設計にあわせて読み替えて下さい。
- アクセスログ
/var/log/httpd/access_log(Apache)、/var/log/nginx/access.log(Nginx)を確認しましょう。以下のような事象が原因で、メモリ使用率が上昇している可能性があります。- POSTリクエストの大量発生
- ファイルアップロード処理の大量発生
- レスポンスサイズが異常に大きいレスポンスの返却
- エラーログ
/var/log/httpd/error_log(Apache)、/var/log/nginx/error.log(Nginx)を確認しましょう。例えば、メモリ不足によりworkerプロセスが起動できていなかったり、異常終了している事象が確認できるかもしれません。
APサーバのログ
APサーバのログに出力されている情報から、CPU使用率上昇の原因を特定できることがあります。ここでは、tomcatを例にとってみましょう。
- catalina.out
Tomcatの標準出力、標準エラーが出力されるログになります。OutOfMemoryErrorやExceptionが出力されていた場合、メモリ上昇の原因となっている可能性があるので、解析を進めましょう。 - gc.log
ヒープ領域のメモリ使用量が増加していることで、GC(ガベージコレクション)が通常より頻発していることがないか確認しましょう。
※tomcatにおけるgc.logの有効化
tomcatにおいて、GCに関するログはデフォルトでは出力されません。下記の設定を追加して、gc.logが出力されるようにしておくことを推奨します。
[root@quiz ~]# vi /opt/tomcat/bin/setenv.sh
[root@quiz ~]# cat /opt/tomcat/bin/setenv.sh
~~Omitted~~
## GC Log Setting
-Xlog:gc*,safepoint:file=$CATALINA_BASE/logs/gc.log:time,level,tags:filecount=5,filesize=10M"
[root@quiz ~]#
[root@quiz ~]# systemctl restart tomcat
[root@quiz ~]#
以下のようにGCに関するログが出力されていれば成功です。以下の例では正常な範囲でマイナーGCが発生していることが確認できます。
[2025-11-03T21:57:11.276+0900][info][safepoint ] Safepoint "ICBufferFull", Time since last: 894905347 ns, Reaching safepoint: 7277 ns, Cleanup: 159379 ns, At safepoint: 3260 ns, Total: 169916 ns
[2025-11-03T21:57:11.352+0900][info][gc,start ] GC(0) Pause Young (Normal) (G1 Evacuation Pause)
[2025-11-03T21:57:11.353+0900][info][gc,task ] GC(0) Using 2 workers of 4 for evacuation
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Pre Evacuate Collection Set: 0.3ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Merge Heap Roots: 0.2ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Evacuate Collection Set: 31.4ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Post Evacuate Collection Set: 2.0ms
[2025-11-03T21:57:11.389+0900][info][gc,phases ] GC(0) Other: 0.7ms
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Eden regions: 13->0(14)
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Survivor regions: 0->2(2)
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Old regions: 2->4
[2025-11-03T21:57:11.389+0900][info][gc,heap ] GC(0) Humongous regions: 0->0
[2025-11-03T21:57:11.389+0900][info][gc,metaspace] GC(0) Metaspace: 6598K(6848K)->6598K(6848K) NonClass: 5909K(6016K)->5909K(6016K) Class: 689K(832K)->689K(832K)
[2025-11-03T21:57:11.389+0900][info][gc ] GC(0) Pause Young (Normal) (G1 Evacuation Pause) 14M->4M(60M) 37.236ms
[2025-11-03T21:57:11.389+0900][info][gc,cpu ] GC(0) User=0.03s Sys=0.04s Real=0.04sDBサーバのログ
DBサーバのログに出力されている情報から、メモリ使用率の上昇要因を特定できる場合があります。ここでは一例として、PostgreSQLのログを確認する方法を紹介します。
- postgresql*.log
PostgreSQLデータベース内部で発生した各種動作や異常を記録するログファイルです。メモリ使用率が上昇している場合、このログに関連する事象が出力されていないか確認してみてください。下記のようなログが出ていたら、メモリ使用率上昇の原因である可能性があります。- ERROR: out of memory DETAIL: Failed on request of size 16777216.
メモリが足りておらずメモリ確保に失敗しています。たとえばwork_mem(ソート・ハッシュ処理用メモリ)のリークがないか、などを疑ってみましょう。 - LOG: temporary file: path “base/pgsql_tmp/pgsql_tmp1234”, size 204800kB
work_memが上限を超えて一時ファイルが作成されています。ソート、ハッシュ処理が急増している可能性があります。
- ERROR: out of memory DETAIL: Failed on request of size 16777216.
メモリダンプの解析
リソース解析やログ解析でも原因が特定できない場合、最終手段としてメモリダンプを解析する方法があります。ただし取得することでOSが停止しますので、商用運転中に意図的に取得することはできません。OSがダウンしてしまった際に備えて、自動取得する設定を入れておくことを推奨します。
メモリダンプの解析方法については以下の記事でまとめているので、参照ください。
【初心者向け】Linuxカーネルのメモリダンプ取得・解析|kdump/crash 実践ガイド
メモリ使用率上昇時の暫定対処
メモリ使用率上昇が続くと、システム全体のパフォーマンスに影響したり、場合によっては重要なプロセスがダウンする可能性があるので、早々に暫定対処を講じることを検討してください。原因次第ではありますが、OSレイヤの対処を中心に暫定対処例をご紹介します。
下記の通り、bashプロセスがメモリを占有している状況を例にとって、対処を実施してみましょう。ちなみにtopコマンド実行後に「M」を押下することで、メモリ使用率が高い順に並び変えることができます。
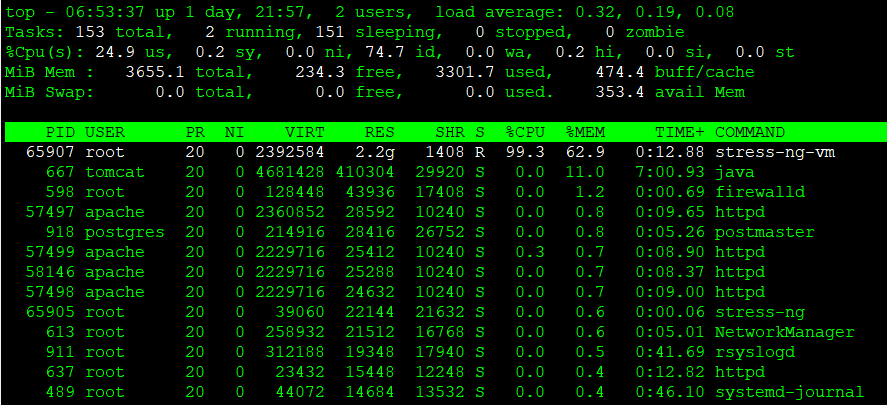
※ stress-ng(負荷掛けツール)を使って、メモリ使用率を上昇させています。
stress-ng --vm 1 --vm-bytes 90% --vm-keepプロセス停止
メモリ使用率上昇の原因となっているプロセスが特定できた場合、当該プロセスを停止するのが効果的です。ただし停止してもサービス提供に影響が出ないことを入念に確認したうえで、対処を実施してください。
killコマンド
killコマンドによりプロセスを停止してみましょう。killコマンドの引数にPIDを指定して実行して下さい。下記の通り、停止されたことを示すメッセージが標準出力に表示されます。
[root@quiz ~]# kill 65907
[root@quiz ~]#プロセスがハングしているなどの理由で、killコマンド(デフォルトは -15=SIGTERM)で停止できないケースがあります。その場合は、オプションkillコマンドに -9(SIGKILL)をつけて強制終了させましょう。
[root@quiz ~]# kill -9 65907
[root@quiz ~]#systemctl stopコマンド
今回の例では適用できませんが、問題があるサービスが特定できており停止しても問題ない場合は、killコマンドではなくsystemctl stopコマンドで停止するようにしましょう。
リソース上限の設定
メモリ使用量が上昇しているプロセスを特定できたものの、当該プロセスを常時停止できない場合、フェイルセーフとしてメモリ使用量の上限を設定する方法が有効なケースがあります。
Linux では、cgroup(systemd の MemoryMax など)や ulimit を用いて、特定のプロセスに対してメモリ使用量の上限を設定することが可能です。ただし、上限値に達した場合、メモリ割り当てに失敗する、または OOM Killer によりプロセスが強制終了される可能性があります。
そのため、本設定は万が一の暴走時に他のプロセスやシステム全体への影響を抑えるための安全装置として利用するものであり、メモリ使用量増加の根本原因を解決する恒久対策にはならない点に注意が必要です。
メモリ容量の拡張
物理サーバでは対応が難しい場合がありますが、仮想サーバであればメモリ容量の拡張は比較的容易にメモリ拡張が実施できます。恒常的に物理メモリが不足していることが明確な場合には、有効な対処となる可能性があります。
ただし、メモリリークやキャッシュの異常増加などが原因の場合、メモリを増設しても問題が再発する可能性があるため、原因を特定した上で最終手段として検討することが重要です。
メモリ使用率上昇時の恒久対処
恒久対処とは、メモリ使用率が上昇する根本原因を解消するための対応を指します。以下に代表的な例を示します。
- アプリケーションの修正
メモリリークや不要なオブジェクト保持などを修正し、必要に応じてライブラリのアップデートを行ったアプリケーションをリリースする。 - プロセス・ワークロード設計の修正
Web サーバの worker 数や AP サーバのスレッド数など、同時実行数に関する設計を見直し、ミドルウェアの設定を修正する。 - メモリ設計の見直し
Java を利用している場合は、JVM のメモリ設計(Heap サイズ、GC 設計など)を見直し、メモリ使用特性に合わせて設定を調整する。 - バッチ処理の設計改善
大量データの一括ロードを避け、処理の分割や実行タイミングの調整により、メモリ負荷が集中しないよう設計を改善する。
まとめ
Linux サーバのメモリ使用率上昇は、放置すると性能劣化やサービス停止につながるため、迅速かつ体系的な対応が重要です。本記事で解説したポイントを以下に整理します。
- まず全体像を把握する
- free、/proc/meminfo で available メモリ を確認
- vmstat でスワップイン/アウトの有無を確認
- メモリを消費している主体を特定する
- top、ps でメモリ使用量の多いプロセスを洗い出す
- smem、pmap で実使用量や内訳(ヒープ/共有メモリ)を確認
- slabtop でカーネルメモリの異常増加を確認
- ログから原因の裏付けを取る
- OSログで OOM Killer やメモリ割り当て失敗の有無を確認
- Web/AP/DB サーバログから負荷増大や異常動作を特定
- 影響を抑えるための暫定対処
- 問題プロセスの停止・再起動
- cgroup や ulimit によるメモリ使用量制限
- 必要に応じたメモリ増設
- 再発防止のための恒久対処
- アプリケーションのメモリリーク修正
- プロセス数・スレッド数など設計の見直し
- JVM やバッチ処理のメモリ設計改善
メモリトラブル対応では、「数値で現状を把握 → プロセス・ログで原因を絞り込み → 暫定対処で被害を抑え → 恒久対策で再発防止」という流れを意識することが、商用システムにおいて最も実践的なアプローチです。


コメント