イントロ
今回はOracle RACにおけるキャッシュフュージョンについて説明します。キャッシュフュージョンとは各インスタンスが持っているデータに関する処理に一貫性を持たせるための機能であり、複数インスタンスに対する各種DML処理を高速化する仕組みとなります。一方で複雑なノード間処理が発生することにより、逆に性能劣化であったり思わぬトラブルが生じることが少なくありませんので、しっかり仕組みを理解して適切な設計およびトラブル対応をできるようにしておくことが大切です。
Oracle RACの基本的な内容については下記の記事に記載しているので、合わせて見てもらえればと思います。
Oracle RACの仕組みを理解しよう ~ClusterwareおよびASMで実現する機能について~
Oracle RACの仕組みを理解しよう ~データベース接続および負荷分散の仕組みについて~
データ一貫性を保つための仕組み
Oracle RAC構成において各種DML処理によるデータの一貫性を保つために、GRD (Global Resource Directory)が管理しているデータブロックに関する最新情報を用いてGES (Global Enqueue Service)およびGCS (Global Cache Service)というプロセスが管理を行っています。
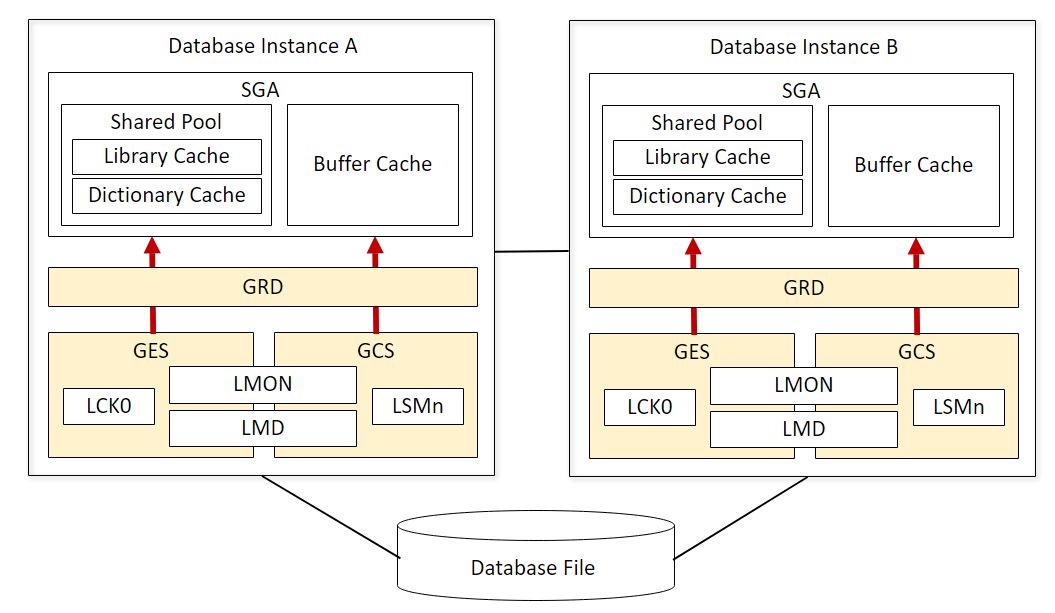
| GRD (Global Resource Directory) | データブロックの状態を記録しておく内部データベースです。本データの保存用にメモリ容量を使うので、Oracle RACを使用する場合はSGAを10%程度多く確保することが必要となります。 |
| GES (Global Enqueue Service) | ローカルおよびグローバルで共有されるエンキュー処理を調整するサービスです。デッドロック検知やリクエストタイムアウトの制御に関連しています。 |
| GCS (Global Cache Service) | 複数のOracle RACインスタンスのバッファキャッシュ内のデータブロックへのアクセスを調整し、キャッシュ一貫性を提供するグローバル・リソースであり、キャッシュ フュージョンを実装する主要な制御プロセスとなります。最新のデータブロックの情報を把握し、インスタンス間のブロック転送も行います。LMSn (Global Cache Service processes) やLMD (Global Enqueue Service Daemon) などのさまざまなバックグラウンド プロセスによって実装されています。 |
| LMON (Global Enqueue Service Monitor) | クラスタ全体を監視して、グローバルリソースを管理しています。インスタンスやプロセスの異常終了、およびGESやGCSに関連するリカバリを管理しています。 |
| LMD (Global Enqueue Service Daemon) | Global Enqueue Serviceのリソース要求を管理するリソースエージェントプロセスとなります。デッドロック検出およびGlobal Enqueue Serviceの要求も処理します。 |
| LCK0 (Instance Enqueue Process) | ライブラリキャッシュ要求などのデータブロック以外のリソースに対する要求を管理するプロセスとなります。 |
| LMSn (Global Cache Service Process) | Oracle RACインスタンス間のリソースを制御してキャッシュフュージョンを実現する主要プロセスとなります。GCS要求やブロック転送などのGCS関連のメッセージ送受信および処理を行います。 |
キャッシュフュージョンの仕組み
ここではGCSによるキャッシュフュージョンの仕組みを説明します。一例として片方のインスタンスで更新されたデータブロックを別のインスタンスから参照する流れを記載します。また、片ノードにおける更新処理がCommitされているかどうかで少し挙動が変わってきますので分けて説明させていただきます。
片ノードにおける更新処理がCommitされている場合
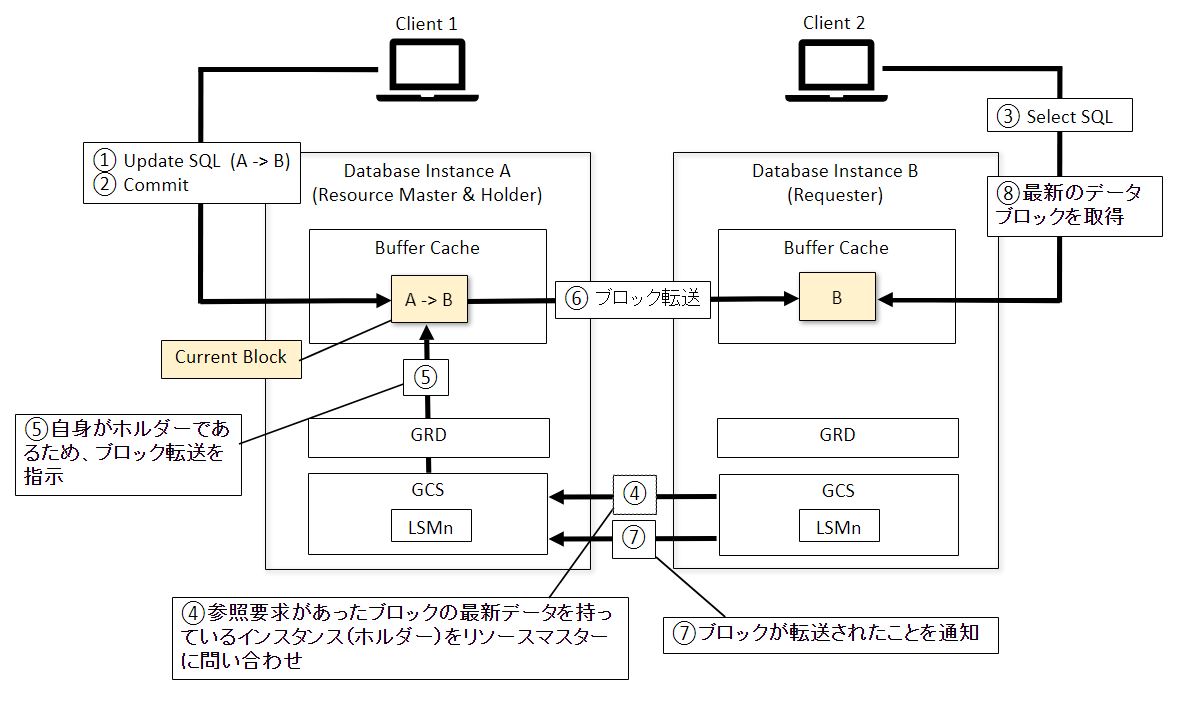
- インスタンスAに対してUpdate文を実行して、データブロック(Current Block)の値をAからBに更新
- Update文をコミット
- インスタンスBに対してSelect文を実行して、1.で更新したデータに対して参照要求を実施
- GCSにより、参照要求があったブロックのホルダーをリソースマスターに問い合わせ
ホルダー:最新のブロックを有しているインスタンス
リソースマスタ:最新のブロックを有しているインスタンスを把握しているインスタンス
※今回の例だとインスタンスAがリソースマスターかつホルダーとなっているが、別々のインスタンスになることもある。 - インスタンスAがホルダーであるため、GCSがインスタンスBに転送を指示
- Current BlockをインスタンスBに転送
- インスタンスAがCurrent Blockを受け取ったことをインスタンスBに通知
- インスタンスBにて最新のブロック情報を参照
片ノードにおける更新処理がCommitされていない場合
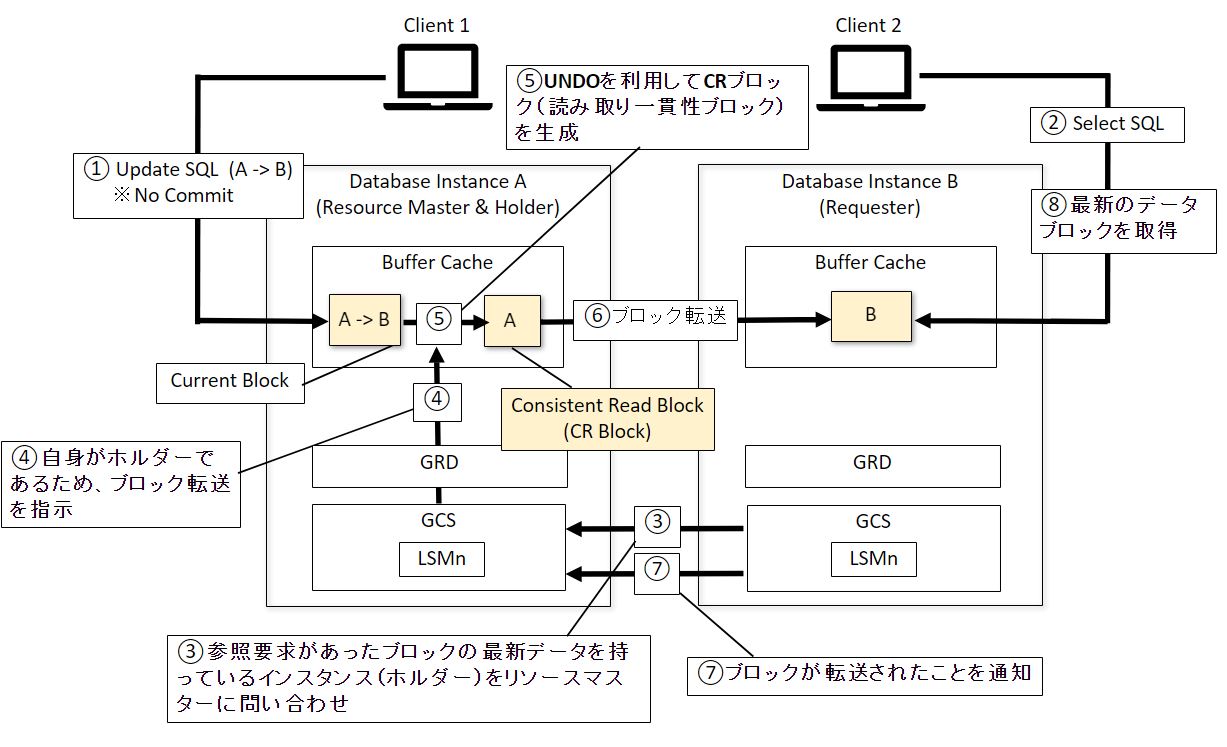
- インスタンスAに対してUpdate文を実行して、データブロック(Current Block)の値をAからBに更新 ※Update文のコミットなし
- インスタンスBに対してSelect文を実行して、1.で更新したデータに対して参照要求を実施
- GCSにより、参照要求があったブロックのホルダーをリソースマスターに問い合わせ
- インスタンスAがホルダーであるため、GCSがインスタンスBに転送を指示
- UNDOを利用してCRブロック(読み取り一貫性ブロックを生成)
- CR BlockをインスタンスBに転送
- インスタンスAがCR Blockを受け取ったことをインスタンスBに通知
- インスタンスBにて最新のブロック情報を参照
まとめ
ここまで読んでいただきありがとうございました。Oracle RACにおけるキャッシュフュージョンの仕組みをご理解いただけたでしょうか。Oracle RACを使っているとキャッシュフュージョン関連のトラブルはつきものです。ぜひ仕組みを詳細に理解してもらえればと思います。他にもOracle関連の記事をいくつか書いてますので、そちらもぜひご参照ください。
Oracle RACの仕組みを理解しよう ~ClusterwareおよびASMで実現する機能について~
【Oracle】メモリ/ファイルアーキテクチャおよび管理方法についてまとめてみた。
【Oracle】SPFILEに関する情報をまとめてみた。
参考文献
津島博士のパフォーマンス講座 第79回 Real Application Clustersの待機イベントについて

Oracle Real Application Clusters(Oracle RAC)のキモ ~Cache Fusionに注目する~



https://www.oracle.com/jp/a/ocom/docs/jp-db-technight-content/02-20170728-discussionnight-rac2.pdf

コメント